Writing about aerospace and electronic systems, particularly with defense applications. Areas of interest include radar, sonar, space, satellites, unmanned plaforms, hypersonic platforms, and artificial intelligence.
An International Team of Scientists Outline Vision for Space-Air-Ground Integration in 6G Networks
A
comprehensive new study published in IEEE's Journal on Selected Areas
in Communications outlines how future 6G wireless networks will need to
seamlessly integrate satellites, aerial platforms, and ground stations
to provide truly global connectivity. The international research team,
led by scientists from the University of Electronic Science and
Technology of China, details the architecture and key technologies
needed to realize this space-air-ground integrated network (SAGIN)
vision.
The researchers explain that while 5G networks primarily
focus on terrestrial infrastructure, 6G will require a three-dimensional
approach combining low Earth orbit satellites, high-altitude platforms
like balloons and drones, and traditional ground-based cell towers. This
integrated architecture aims to overcome current limitations in
coverage, especially in remote areas, while enabling new capabilities in
sensing and computing.
"Traditional ground-based networks alone
cannot meet the diverse needs of future applications," explains lead
author Yue Xiao. "By intelligently combining space, air and ground
assets, we can achieve truly ubiquitous coverage while also supporting
emerging technologies like quantum computing and artificial intelligence
at the network edge."
One of the key challenges identified is
managing communications across these different domains. The researchers
outline various approaches including new waveform designs, spectrum
sharing techniques, and intelligent routing algorithms. They also
emphasize the need for advanced computing capabilities distributed
throughout the network to process data closer to where it's generated.
The
paper presents detailed technical recommendations across the physical,
MAC and network layers of this integrated architecture. The authors note
that while some enabling technologies already exist, significant
research and development work remains, particularly around seamless
handovers between different network segments and efficient resource
allocation.
Looking ahead, the researchers envision this
integrated network architecture enabling transformative applications in
areas like autonomous vehicles, smart cities, and disaster response.
However, they caution that realizing this vision will require close
collaboration between the satellite, aviation and telecommunications
industries, along with supportive government policies and standards.
The
research represents a unique collaboration between leading institutions
in wireless communications research. The team includes scientists from
the University of Electronic Science and Technology of China, the Royal
Institute of Technology in Sweden, King Abdullah University of Science
and Technology in Saudi Arabia, RMIT University in Australia, and the
European Space Agency. This diverse international collaboration brought
together expertise spanning satellite communications, wireless networks,
and advanced computing systems.
Professor Ming Xiao from KTH
Royal Institute of Technology and Professor Mohamed-Slim Alouini from
KAUST contributed crucial insights on network architecture and
integration strategies, while Dr. Akram Al-Hourani from RMIT University
and Dr. Stefano Cioni from the European Space Agency provided valuable
perspectives on practical implementation challenges and satellite system
requirements. The work was supported by multiple research grants from
national science foundations and European research programs.
Summary
Here's a summary of the key aspects of this comprehensive paper on Space-Air-Ground Integrated Networks (SAGIN) for 6G:
The paper presents a thorough examination of how SAGIN will be a fundamental component of 6G infrastructure, combining three main segments:
Space Network: Consists of satellites in various orbits (LEO, MEO, GEO) providing global coverage and connectivity. LEO satellites in particular will play a crucial role due to their proximity to Earth and growing computing capabilities.
Air Network: Includes aerial platforms like High Altitude Platforms (HAPs), unmanned aerial vehicles (UAVs), and balloons that help bridge gaps between satellite and ground networks while addressing satellite communication limitations.
Ground Network: Traditional terrestrial infrastructure including cellular networks, mobile ad-hoc networks, and wireless local area networks.
Key technological innovations and challenges discussed include:
- Multi-Band Communication: Integration of various frequency bands including mmWave, THz, and optical wireless communication to meet increasing data demands
- Computing Integration: Emphasis on combining communication and computing capabilities across all network segments, including mobile edge computing, federated learning, and multi-agent reinforcement learning
- Physical Layer Advances: New developments in channel measurement, waveform design, modulation methods, and channel coding specific to SAGIN environments
- Network Layer Solutions: Novel approaches to traffic offloading, routing algorithms, and task scheduling across the integrated network
The paper also highlights emerging technologies that will enable SAGIN:
- Software-Defined Networking (SDN) and Network Function Virtualization (NFV)
- Digital Twin technology for network modeling and optimization
- Artificial Intelligence integration across all network layers
- Integrated sensing and communication capabilities
Finally, the paper discusses future trends and challenges, particularly around:
- Internet of Space Things (IoST)
- Integration of communication, sensing, and computation capabilities
- Need for improved spectrum management and resource allocation
- Requirement for seamless mobility management across different network segments
This work provides a comprehensive roadmap for the development of SAGIN as a core component of future 6G networks while highlighting key research areas that need attention from both academia and industry.
Projected Future Paths
Here's an expanded analysis of the future trends, challenges, and required technical developments for SAGIN in 6G:
Key Technical Challenges:
1. Physical Layer:
- Need for innovative air interface frameworks to handle extreme distances and high mobility
- System-level joint channel measurements across all three network segments
- Development of unified waveform and modulation methods suitable for diverse channel characteristics
- Integration of RIS (Reconfigurable Intelligent Surface) technology while addressing power consumption and hardware implementation challenges
2. MAC Layer:
- Cognitive spectrum utilization across different network segments
- Efficient handover management between satellites, aerial platforms, and ground stations
- Development of robust redundancy measures and restoration techniques
- Complex mobility management for dynamic network topology
3. Network Layer:
- Balanced traffic distribution across varying user densities and QoS requirements
- Adaptive data scheduling for multi-connection concurrent transmission
- Smart routing solutions for simultaneous transmissions across heterogeneous networks
- Resource allocation optimization across all network segments
Future Trends:
1. Internet of Space Things (IoST):
- Integration of CubeSats for expanded connectivity
- Development of space-based sensing and computing capabilities
- Enhanced inter-satellite communication protocols
- Need for standardized space-ground interfaces
2. Communication-Sensing-Computation Integration:
- Joint design of sensing and communication systems
- Development of integrated waveforms serving multiple purposes
- Enhanced edge computing capabilities across all network segments
- AI/ML integration for network optimization and management
Required Technical Developments:
1. Infrastructure:
- Advanced satellite technologies with improved processing capabilities
- More efficient and cost-effective aerial platforms
- Enhanced ground station networks
- Improved inter-segment communication links
2. Protocols and Standards:
- New protocols for seamless handover between segments
- Standardized interfaces for cross-layer communication
- Enhanced security protocols for integrated networks
- Quality of Service (QoS) frameworks spanning all segments
3. Computing and Intelligence:
- Distributed computing architectures across all segments
- Enhanced edge computing capabilities in aerial and space platforms
- AI/ML models optimized for space-air-ground scenarios
- Real-time decision-making capabilities
4. Resource Management:
- Dynamic spectrum allocation mechanisms
- Energy-efficient operation strategies
- Compute resource optimization across segments
- Bandwidth allocation and management systems
Implementation Challenges:
1. Economic:
- High deployment costs for satellite and aerial platforms
- Need for substantial infrastructure investment
- Operating cost optimization across network segments
- Business model development for integrated services
2. Regulatory:
- Spectrum allocation across different jurisdictions
- International coordination requirements
- Safety and security regulations
- Environmental impact considerations
3. Technical Coordination:
- Integration of different technology standards
- Interoperability between various systems
- Synchronization across network segments
- Management of diverse equipment lifecycles
Research Priority Areas:
1. Channel Modeling:
- Comprehensive models for all network segments
- Dynamic channel characterization
- Impact of atmospheric conditions
- Multi-path and interference effects
2. Network Architecture:
- Scalable and flexible designs
- Fault tolerance and redundancy
- Security integration at all levels
- Support for diverse applications
3. Performance Optimization:
- End-to-end latency reduction
- Throughput maximization
- Energy efficiency improvement
- Coverage optimization
This comprehensive development roadmap requires coordinated efforts from industry, academia, and regulatory bodies to realize the full potential of SAGIN in 6G networks. Success will depend on addressing these challenges while maintaining focus on practical implementation and economic viability.
Y. Xiao et al., "Space-Air-Ground Integrated Wireless Networks for 6G: Basics, Key Technologies, and Future Trends," in IEEE Journal on Selected Areas in Communications, vol. 42, no. 12, pp. 3327-3354, Dec. 2024, doi: 10.1109/JSAC.2024.3492720.
Abstract: With the expansive deployment of ground base stations, low Earth orbit (LEO) satellites, and aerial platforms such as unmanned aerial vehicles (UAVs) and high altitude platforms (HAPs), the concept of space-air-ground integrated network (SAGIN) has emerged as a promising architecture for future 6G wireless systems. In general, SAGIN aims to amalgamate terrestrial nodes, aerial platforms, and satellites to enhance global coverage and ensure seamless connectivity. Moreover, beyond mere communication functionality, computing capability is increasingly recognized as a critical attribute of sixth generation (6G) networks. To address this, integrated communication and computing have recently been advocated as a viable approach. Additionally, to overcome the technical challenges of complicated systems such as high mobility, unbalanced traffics, limited resources, and various demands in communication and computing among different network segments, various solutions have been introduced recently. Consequently, this paper offers a comprehensive survey of the technological advances in communication and computing within SAGIN for 6G, including system architecture, network characteristics, general communication, and computing technologies. Subsequently, we summarize the pivotal technologies of SAGIN-enabled 6G, including the physical layer, medium access control (MAC) layer, and network layer. Finally, we explore the technical challenges and future trends in this field.
- Political sensitivity led to more conservative research approaches
- Loss of original interdisciplinary environment that sparked breakthroughs
These changes transformed RAND from an innovative basic research powerhouse into a more conventional policy think tank.
Current CEO Jason Matheny argues RAND remains influential, citing recent contributions in:
- Early analysis of China's military buildup
- Russian military capabilities assessment
- U.S. military vulnerabilities in the Pacific
- Nuclear strategy and drone technology
- Military personnel issues and PTSD research
- AI integration in defense
While RAND continues as a respected think tank, it no longer produces the same fundamental breakthroughs that characterized its early years, partly due to changed funding environment and institutional priorities.
Our article was originally published in Asterisk Magazine. Today,ChinaTalk is rereleasing it alongside exclusive commentary from Jason Matheny, CEO of RAND at the end of the post.
Today, RAND remains a successful think tank — by some metrics, among the world’s best.1
In 2022, it brought in over $350 million in revenue, and large
proportions still come from contracts with the US military. Its graduate
school is among the largest for public policy in America.
But
RAND’s modern achievements don’t capture the same fundamental policy
mindshare as they once did. Its military reports may remain influential,
but they hold much less of their early sway, as when they forced the
U.S. Air Force to rethink several crucial assumptions in defense policy.
And RAND’s fundamental research programs in science and technology have
mostly stopped. Gone are the days when one could look to U.S. foreign
policy or fundamental scientific breakthroughs and trace their
development directly back to RAND.
How was magic made in Santa Monica? And why did it stop?
Economists,
physicists, and statisticians — civilian scientists to that point not
traditionally valued by the military — first proved their utility in the
late stages of World War II operational planning. American bomber units
needed to improve their efficiency over long distances in the Pacific
theater. The scientists hired by the Army Air Force proposed what at the
time seemed a radical solution: removing the B-29 bomber’s armor to
reduce weight and increase speed. This ran counter to USAAF doctrine,
which assumed that an unprotected plane would be vulnerable to Japanese
air attacks. The doctrine proved incorrect. The increased speed not only
led to greater efficiency, it also led to more U.S. planes returning
safely from missions, as Japanese planes and air defense systems were
unable to keep up.2
Civilian scientists were suddenly in demand. By the end of the war, all
USAAF units had built out their own operations research departments to
optimize battle strategy. When the war ended, the question turned to how
to retain the scientific brain trust it had helped to assemble.
General
Henry “Hap” Arnold, who had led the Army Air Force’s expansion into the
most formidable air force in the world, had started to consider this
question long before the war had ended. He found an answer in September
1945, when Franklin Collbohm, a former test pilot and executive at
Douglas Aircraft, walked into Arnold’s office with a plan: a
military-focused think tank staffed by the sharpest civilian scientists.
Collbohm did not have to finish describing his idea before Arnold
jumped and agreed. Project RAND was born.
Arnold, along with
General Curtis LeMay — famous for his “strategic bombing” of Japan,
which killed hundreds of thousands of civilians — scrounged up $10
million from unspent war funds to provide the project’s seed money,
which was soon supplemented with a grant from the Ford Foundation. This
put RAND into a privileged position for a research organization: stably
funded.
On top of that financial stability, RAND built what would
become one of its greatest organizational strengths: a legendarily
effective culture, and a workforce to match it.
In an internal memo, Bruno Augestein,
a mathematician and physicist whose research on ballistic missiles
helped usher in the missile age, highlighted a set of factors that
catalyzed RAND’s early success. In short: RAND had the best and
brightest people working with the best computing resources in an
environment that celebrated excellence, welcomed individual quirks, and
dispensed with micromanagement and red tape.
Early
RAND leadership was, above all else, committed to bringing in top talent
and jealously guarded the sort of intellectual independence to which
their academic hires were accustomed. Taking the mathematics department
as an example, RAND hired John Williams, Ted Harris, and Ed Quade
to run it. While these were accomplished mathematicians in their own
right, these three were also able to attract superlative talents to work
under and around them. As Alex Abella writes in Soldiers of Reason,
his history of RAND, “No test for ideological correctness was given to
join, but then none was needed. The nation’s best and brightest joining
RAND knew what they were signing on for, and readily accepted the vision
of a rational world — America and its Western allies — engaged in a
life-and-death struggle with the forces of darkness: the USSR.”
As
the Cold War intensified, the mission became the sell. The aim of RAND,
as the historian David Hounshell has it, “was nothing short of the
salvation of the human race.”3
The researchers attracted to that project believed that the only
environment in which that aim could be realized was independent of the
Air Force, its conventional wisdom, and — in particular — its
conventional disciplinary boundaries
RAND’s earliest
research aligned with the USAF’s (the Army Air Force had become its own
service branch in 1947) initial vision: research in the hard sciences to
attack problems like satellite launches and nuclear-powered jets.4
However, the mathematician John Davis Williams, Collbohm’s fifth hire,
was convinced that RAND needed a wider breadth of disciplines to support
the Air Force’s strategic thinking. He made the case to General LeMay,
who supervised RAND, that the project needed “every facet of human
knowledge to apply to problems.”5
To that end, he argued for recruiting economists, political scientists,
and every other kind of social scientist. LeMay, once convinced,
implored Williams to hire whoever it took to get the analysis right.
And
so they did. RAND’s leadership invested heavily in recruiting the best
established and emerging talent in academia. An invitation-only
conference organized by Williams in New York in 1947 brought together
top political scientists (Bernard Brodie), anthropologists (Margaret
Mead), economists (Charles Hitch), sociologists (Hans Speier), and even a
screenwriter (Leo Rosten). The promise of influence, exciting
interdisciplinary research, and complete intellectual freedom drew many
of the attendees to sign up.
Within two years, RAND had assembled
200 of America’s leading academics. The top end of RAND talent was (and
would become) full of past (and future) Nobel winners, and Williams
worked around many constraints — and eccentricities — to bring them on.
For instance, RAND signed a contract with John von Neumann to produce a
general theory of war, to be completed during a small slice of his time:
that spent shaving. For his shaving thoughts, von Neumann received $200
a month, an average salary at the time.
Beyond the biggest names, RAND was “deliberate, vigorous, and proactive” in recruiting the “first-rate and youthful staff” that made up most of its workforce. The average age of staff in 1950 was under 30.6
Competition between them helped drive the culture of excellence. Essays
and working papers were passed around for comments, which were copious —
and combative. New ideas had to pass “murder boards.” And the
competition spilled into recreational life: Employees held tennis
tournaments and boating competitions. James Drake, an aeronautical
engineer, invented the sport of windsurfing.
The wives of RAND employees — who were, with a few notable exceptions,
almost all male — even competed through a cooking club where they tried
to make the most "exotic" recipes.
After bringing in such extraordinary talent, RAND’s leadership trusted them to largely self-organize.Department
heads were given a budget and were free to spend it as they felt fit.
They had control over personnel decisions, which allowed them the
flexibility to attract and afford top talent. As a self-styled
“university without students,” RAND researchers were affiliated with
departments with clear disciplinary boundaries, which facilitated the
movement of researchers between RAND and academia. But in practice, both
departments and projects were organized along interdisciplinary lines.
The
mathematics department brought on an anthropologist. The aeronautics
department hired an MD. This hiring strategy paid off in surprising
ways. For instance, while modeling the flow of drugs in the bloodstream,
a group of mathematicians stumbled upon a technique
to solve a certain class of differential equations that came to be used
in understanding the trajectory of intercontinental ballistic missiles.
The caption of this image, from the May 11, 1959, issue of Life
magazine, reads: ‘After-hours workers from RAND meet in home of Albert
Wohlstetter (foreground), leader of RAND’s general war studies. They are
economists gathered to discuss study involving economic recovery of
U.S. after an all-out war.’ Leonard McCombe / The LIFE Picture
Collection via Getty Images.
RAND
was at the forefront of a postwar explosion in federal funding for
science. Hundreds of millions of dollars poured into universities, think
tanks, and industrial R&D labs. Almost all of it was directed
toward one purpose: maintaining military superiority over the Soviet
Union. In 1950, over 90% of the federal research budget came from just
two agencies: the Atomic Energy Commission and the Department of
Defense.7 Significant portions of this funding went toward basic research with no immediate military applications.8
Vannevar Bush, the influential head of the war-era Office of Scientific
Research and Development, had argued for this approach in his 1945 book
Science, the Endless Frontier: Freeing up
scientists to follow their own research interests would inevitably lead
to more innovation and ensure American technological dominance. Bush’s
was not the only, or even the dominant, view of how postwar science
should be organized — most science funding still went toward applied
research — but his views helped inform the organization of a growing
number of research institutions.9
No organization embodied this model more than RAND. Air Force contracts
were the financial backbone of the organization. They provided the
money required to run RAND, while profits were used to fund basic
research. In the 1950s, USAF contracts comprised 56% of RAND’s work,
while other sponsors made up just 7%.10
That left more than a third of RAND’s capacity open to pursue its own
agenda in basic research. Many of the developments made there would be
used in their applied research, making it stronger — and more profitable
— in the process. This flywheel would become critical to RAND’s
success.
Not all of these
developments were successful, especially at first. RAND’s early research
efforts in systems analysis — an ambitious pursuit in applying
mathematical modeling that RANDites were optimistic could produce a
holistic “science of warfare” — were flops. The first project, which
aimed to optimize a strategic bombing plan on the Soviet Union, used
linear programming, state-of-the-art computing, and featured no fewer
than 400,000 different configurations of bombs and bombers. It proved of
little use to war planners. Its assumptions fell prey to the
“specification problem:” trying to optimize one thing, in this case,
calculating the most damage for the least cost led to misleading and
simplistic conclusions.11
But RAND would soon find its footing, and a follow up to this work became a classic of the age. The 1954 paper Selection and Use of Strategic Air Bases
proved the value of RAND’s interdisciplinary approach — though its
conclusions were at first controversial. Up to the 1950s, there had been
little analysis of how the Strategic Air Command, responsible for the
United States’s long range bomber and nuclear deterrent forces, should
use its Air Force bases. At the time, the SAC had 32 bases across Europe
and Asia. The study, led by political scientist Albert Wohlstetter,
found that the SAC was dangerously vulnerable to a surprise Soviet
attack. The SAC’s radar defenses wouldn’t be able to detect low-flying
Soviet bombers, which could reduce American bombers to ash — and thereby
neutralize any threat of retaliation — before the Americans had a
chance to react. Wohlstetter’s study recommended that the SAC keep its
bombers in the U.S., dispersed at several locations to avoid
concentration at any place.
LeMay, RAND’s original
benefactor and commander of the SAC, resisted Wohlstetter’s conclusions.
He worried the plan would reduce his control over the country’s nuclear
fleet: With the SAC based in the U.S., LeMay would have to cede some
authority to the rest of the U.S. Air Force. He pushed against it many
times, proposing several alternatives in which the SAC kept control over
the bombers, but no plan fully addressed the vulnerabilities identified
by the report.
Undaunted — and sure of his logic —
Wohlstetter pushed his conclusions even further. He proposed a fail-safe
mechanism, where nuclear bombers would have to receive confirmation of
their attack from multiple checkpoints along the way, to prevent rogue
or mistaken orders from being followed. Wohlstetter went around LeMay,
to Defense Secretary Charles Wilson and General Nathan Twining, chairman
of the Joint Chiefs of Staff, who ultimately accepted the study’s
recommendations in full. It took over two decades, but they proved their
value in 1980 when a faulty chip erroneously warned of an impending
Soviet strike. While no order for a retaliatory attack was issued, had
there been one, the fail-safe mechanism would have prevented the bombers
from actually attacking the USSR. Selection and Use of Strategic Air Bases
was a triumph for RAND. Not only had they provided correct advice to
the USAF, they had also proved their independence from the institution’s
internal politics.
And the flywheel would prove its value
many times over. RAND’s basic research helped drive the development and
strategy of ICBMs, the launch of the first meteorological satellite,
and, later, on cost reductions in ICBM launch systems.
RAND’s
conclusions ran counter to USAF doctrine several times — and each time
RAND fought to maintain its independence. When the USAF commissioned
RAND to study the Navy’s Polaris program
— in order to show that it was inferior to the Air Force’s bombers for
nuclear weapon delivery — RAND found that the Polaris missiles were, in
fact, superior. The same happened with another study, which challenged the effectiveness of the B-70 bomber in 1959.
Over time, however, these tensions added friction to the relationship. To make matters worse, between 1955 and 1960, the USAF’s budget declined
in both absolute terms, and relative to the rest of the defense
community. In 1959, the Air Force froze RAND’s budget, presumably due to
the budget cuts — and their disputes with RAND.
This
situation was not unique to the USAF, or to RAND. As the 1950s rolled
into the ’60s, scientists at civilian institutions increasingly moved to
disentangle themselves from their military benefactors. Throughout the
decade, DOD funding for basic research would only continue to decline.12
RAND
weathered the transition by successfully seeking out new customers —
the AEC, ARPA, the Office of the Comptroller, the Office of the
Assistant Secretary of Defense for International Security Affairs (ISA),
NASA, the NSF, the NIH, and the Ford Foundation, to name a few. The
percent of the outside funding coming from the USAF dropped from 95%
when RAND started to 68% in 1959.13
But their success came at a cost: This diversification is what led to
RAND losing its edge in producing the cutting edge of policy and applied
science.
Funding diversification reshaped both RAND’s
culture and output. The increased number of clients made scheduling
researchers’ work harder. Each client expected a different standard of
work, and the tolerance levels for RAND’s previously freewheeling style
varied. The transaction costs of starting a new contract were much
higher and the flexible staffing protocols that had worked for the USAF
in the 1950s needed to be systematized. The larger organization led to
ballooning internal administration expenses.
Along with all of this, RAND’s increased size attracted more political detractors. In 1958, a RAND paper called Strategic Surrender,
which examined the historical conditions for surrender, had generated a
political firestorm. Politicians were furious with RAND for exploring
conditions under which it would be strategic for the U.S. to surrender.
Senators weren’t particularly interested in the study itself, but those
who wanted to run for president (like Stuart Symington of Missouri) used it as evidence that the Eisenhower administration was weak on defense.
The
Senate even passed a resolution (with an 88–2 margin) prohibiting the
use of federal funds for studying U.S. surrender. RAND’s management,
realizing that an intentional misinterpretation of their work
potentially threatened future funding streams, now had to consider the
wider domestic political context of their work. All of these factors
changed RAND’s culture from one that encouraged innovation and
individuality to one that sapped creativity.
But the biggest
change was yet to come. In 1961, Robert McNamara took over the
Department of Defense and brought with him a group of RAND scholars,
commonly called the “Whiz Kids.” Their most important long-term
contribution to U.S. governance was the Planning-Programming-Budgeting
System. PPBS took a Randian approach to resource allocation, namely,
modeling the most cost-effective ways to achieve desired outcomes. In
1965, after President Johnson faced criticism for poor targeting of his
Great Society spending, he required nearly all executive agencies to
adopt PPBS. Many RAND alumni were hired by McNamara and his team to help
with the Great Society’s budgeting process.
In 1965, Henry
Loomis, the deputy commissioner on education, approached RAND about
conducting research on teaching techniques. Franklin Collbohm, RAND’s
founder and then president, declined. He preferred that RAND stay within
the realm of military analysis. RAND’s board disagreed and would
eventually push Collbohm out of RAND in 1967. The board thought it was
time for a change in leadership — and to RAND’s nonmilitary portfolio.
The entry of a new president,
Henry S. Rowen, an economist who had started his career at RAND,
cemented this change. By 1972, the last year of Rowen’s tenure, almost
half of all RAND projects were related to social science. For better or
worse, this eroded RAND’s ability to take on cutting-edge scientific
research and development.
RAND entered domestic policy
research with a splash — or, rather, a belly flop. The politics of
social policy research were markedly different from working with the
DOD. For one, there were substantially more stakeholders — and they were
more vocal about voicing their disagreements. One crucial example is
when RAND proposed police reforms in New York City, but pressure from
the police unions forced them to retract.
John Lindsay, the
Republican mayor of New York, had tasked RAND with improving the New
York Police Department, which had recently been implicated in narcotics
scams, corruption, and police brutality. The report showed that in less
than 5% of the cases in which an officer was charged with a crime or
abusing a citizen did the officers receive anything more than a
reprimand. The findings were leaked to The New York Times, which added to the impression among the police that RAND was the mayor’s mouthpiece.
RAND, for the first time, had to face the reality of local
politics: a sometimes hostile environment, multiple stakeholders who
sometimes acted in bad faith, and none of the free reign that
characterized their first decades. RAND’s experience with the police
report, and the controversy over the study of surrender, led RAND to be
more conservative about the research it put out. And additionally, the
focus on policy research crowded out the scientific research.
For example, beginning in the 1970s, RAND’s applied mathematics research
output slowed to a trickle, before stopping altogether in the 1990s. It
was replaced by mathematics education policy. The same is true for physics, chemistry, and astronomy.
Another emblematic development in the dilution of RAND’s focus was the
founding in 1970 of the Pardee RAND Graduate School, the nation’s first
Ph.D.-granting program in policy analysis. While the idea of training
the next generation in RAND techniques is admirable, RAND in the early
years explicitly defined itself as a “university without students.”
RAND
is still an impressive organization. It continues to produce successful
policy research, which commands the eyes of policymakers in over 82
federal organizations and across dozens of local and even foreign
governments. Still, their work today is inarguably less groundbreaking
and innovative than it was in the ’50s. This relative decline was
partially caused by internal policy choices, and partially by the
eventual loss of their initial team of leading scientists. But part of
it was also inevitable: We no longer live in an era when branches of the
U.S. military can cut massive blank checks to think tanks in the
interest of beating the Soviets. The successes of 1950s RAND do come
with lessons for modern research organizations — about the importance of
talent, the relevance of institutional culture, and the possibilities
of intellectual freedom — but the particular conditions that created
them can’t be replicated. It is remarkable that they existed at all.
The following commentary comes directly from RAND’s CEO, Jason Matheny.
RAND
CEO Jason Matheny here. Your readers may recall from my appearance on
your podcast last year that I, too, am a RAND history nerd. There are
many great details in your Asterisk article about RAND’s early contributions in the 1950s and ‘60s. Thanks for bringing them to life.
RAND’s contributions in the last five decades
have been no less consequential. The world’s challenges are certainly
different from the ones RAND researchers confronted in the early years.
But it is RAND’s ability to reorient itself toward the biggest
challenges that has been our “magic.” We shouldn’t expect or want RAND
to look the same as it did during the Cold War.
I
thought your readers would be interested to pick up where your story
stops. And since your article focuses on national security, I’ll
concentrate my comments there. (That said, there have been just as many breakthroughs in RAND’s social and economic policy analyses over the years.)
RAND’s
security research in the modern era has been forward-looking, has
challenged long-held wisdom, and has anticipated once-unthinkable
threats. And I’m not saying this only as RAND’s CEO. Before I joined
RAND two years ago, I was one of countless people at the White House and
elsewhere in government who relied on RAND analysis to make critical
decisions.
Many recent RAND studies will remain classified for
years. While their full impact will be assessed with time — much as was
the case with RAND’s work in the 1950s and 1960s – they have been among
RAND’s most influential. Below are some examples of projects that we can
describe here:
Russia: RAND was among the first organizations to identify Russia’s growing military capabilities following its 2008 war in Georgia and the threat these posed to new NATO members in the Baltic states. This work prompted important planning and infrastructure changes that are being used today to support Ukraine.
U.S. military power: RAND’s series of overmatchstudies transformed policymakers’ understanding the loss of U.S. military superiority in key areas over time.
Operating in the Pacific theater: RAND was among the first to highlight the vulnerability of the U.S. military’s forward infrastructure in the Pacific and ways to overcome that vulnerability.
Nuclear strategy: RAND’s recent work on nuclear deterrence,
including wargames analyzing nuclear-armed regional adversaries,
brought about a resurgence of deterrence thinking within the
government.
B-21: RAND analysis of penetrating versus standoff bomber capabilities led directly to the decision to establish the B-21 program.
Military forces: RAND‘s work on military personnel, the ability to develop and sustain the all-volunteer force over time, appropriate pay and benefits
for the force, and the vulnerabilities to service members and their
families, has been the primary source of analysis for decisionmakers
within the Department of Defense and Congress.
Drones: RAND’s analysis
of small UAVs and swarming options was the first to analyze how a
sensor grid can substantially strengthen deterrence in the Asia-Pacific
region. Current DoD programs can be traced directly to this pathbreaking
analysis.
PTSD and TBI: RAND’s work on the invisible wounds of war,
PTSD, and traumatic brain injury, was the first careful documentation
of psychological and cognitive injuries from modern combat. This work
launched a society-wide effort to detect and treat such injuries.
Logistics: RAND analysis
prompted the revolution in combat logistics in both the Air Force and
the Army, emphasizing wartime flexibility and resilience as the
organizing principles for supply and maintenance.
AI: RAND was early in systematically evaluating how defense organizations could integrate contemporary AI methods based on deep learning, in evaluating large language models, and in assessing threats to model security.
With
rapid developments in emerging technology and an increasingly
confrontational PRC government, the world needs RAND’s analysis more
than ever. I know that your readers care deeply about these challenges.
Those who want to work toward solutions should consider working at RAND or applying to our new master's degree program in national security policy.
To hear more from Jason, check out the two-hour interview we did last year on ChinaTalk, which was my favorite episode of 2023.
Breakthrough in Satellite Error Correction Improves Space Communications
Scientists and engineers have developed an advanced error correction system for satellite communications that promises to make space-based internet and data transmission more reliable while using less power (Sturza et al., Patent EP1078489A2). The innovation, which combines special coding techniques for both message headers and data payloads, could be particularly valuable for the growing number of low Earth orbit (LEO) satellite constellations providing global internet coverage.
The system uses a technique called "concatenated coding" along with data interleaving to protect against signal disruptions caused by atmospheric interference and satellite movement. What makes this approach unique is that it processes the routing information (headers) and actual message content (payload) separately, allowing satellites to efficiently direct traffic through the network while maintaining data integrity (Poulenard et al., ICSO 2018).
"By optimizing how we handle error correction for different parts of the data stream, we can achieve reliable high-speed communications even under challenging conditions," notes research presented at the International Conference on Space Optics. Recent tests have demonstrated error-free transmission rates of up to 25 gigabits per second between satellites and ground stations using advanced coding techniques (Poulenard et al., ICSO 2018).
The technology arrives as companies deploy thousands of new satellites requiring robust communication systems. Researchers have shown that using specialized Low-Density Parity-Check (LDPC) codes with bit interleaving can achieve near-error-free links at high data rates, potentially enabling the next generation of space-based internet services (Poulenard et al., ICSO 2018)..
Advanced Error Correction Techniques for Satellite Communications: Technical Summary
- Achieves superior performance compared to DVB-S2 standards
- Implements 10 iteration limit for Normalized Min-Sum decoding
- Enables high-throughput decoder implementation
System Advantages:
- Reduced power requirements
- Lower satellite hardware complexity
- Maintained end-to-end coding gain
- Scalable to different constellation architectures
- Compatible with both Earth-fixed and satellite-fixed beam approaches
The architecture particularly excels in handling the unique challenges of LEO satellite communications, including:
- Path loss compensation
- Doppler shift management
- Multipath fading mitigation
- Atmospheric interference correction
This technical implementation represents a significant advancement in satellite communication reliability while maintaining efficient power and processing requirements.
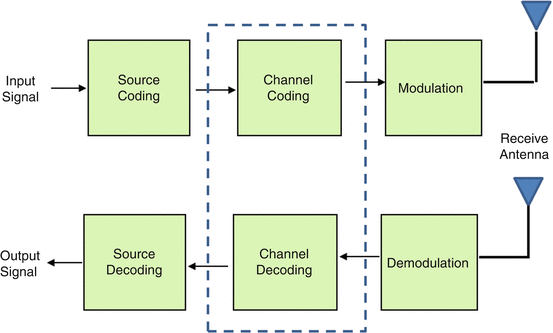
As satellite constellations become integral to global
communication networks, ensuring reliable and efficient data
transmission remains a paramount challenge. Channel coding, which adds
redundancy to transmitted data, is a fundamental technique employed to
enhance the reliability and efficiency of satellite communication
systems. This article delves into the principles of channel coding, its
application in satellite constellations, and its critical role in
maintaining robust communication.
The rise of mega-constellations promises
ubiquitous internet access and expanded mobile connectivity. But
venturing into the vast expanse brings unique challenges. Unlike
terrestrial networks, mobile satellite communications contend with harsh
channel effects like:
Path Loss: The sheer distance between satellites and Earth-bound users weakens the signal.
Doppler Shift: Satellite movement induces frequency variations, distorting the signal.
Multipath Fading: The signal can bounce off various objects, creating distorted replicas that interfere with the original transmission.
These effects elevate the Bit Error Rate
(BER), meaning more errors creep into the data stream. Here’s where
channel coding comes in as a hero, playing a vital role in ensuring
reliable data transmission for mobile satellite constellations.
The Principle of Channel Encoding
Channel encoding involves adding redundant bits to the information
bits to form a coded sequence, which is then transmitted over the
channel. The primary objective of this process is to enable error
detection and correction at the receiver. This technique, known as
forward error correction (FEC), enhances the reliability of data
transmission in the presence of noise and other impairments.
Code Rate
The code rate (r) is a key parameter in channel coding and is defined
as the ratio of information bits (n) to the total number of bits (n +
r), where r represents the number of redundant bits. Mathematically, the
code rate is expressed as:
The equation for code rate (r) remains the same as provided in the passage:
code rate r = n / (n + k)
Here:
k: Number of redundant bits added for n information bits.
n: Number of information bits.
2. Bit Rate at Encoder Output:
The equation for bit rate at the encoder output (Rc) is modified to account for the code rate:
Rc = Rb / r (bit/s)
Here:
Rc: Bit rate at the encoder output (including redundant bits).
Rb: Bit rate at the encoder input (information bits only).
r = Code rate .
Decoding Gain and Eb/N0 Relationship:
The equation for Eb/N0 considering code rate is already provided in the passage:
Eb/N0 = Ec/N0 – 10 log r (dB)
Here:
Eb/N0: Energy per information bit to noise power spectral density ratio (dB).
Ec/N0: Energy per coded bit to noise power spectral density ratio (dB).
r: Code rate
The decoding gain Gcod is defined as the
difference in decibels (dB) at the considered value of bit error
probability (BEP) between the
required values of Eb=N0 with and without coding, assuming equal information bit rate Rb.
These equations, along with the
understanding of code rate, provide a foundation for analyzing and
optimizing channel coding performance in satellite communication
systems.
Encoding Techniques
Two primary encoding techniques are used in mobile satellite networks: block encoding and convolutional encoding.
Block Encoding
In block encoding, the encoder associates redundant bits with each
block of information bits. Each block is coded independently, and the
code bits are generated through a linear combination of the information
bits within the block. Cyclic codes, particularly Reed-Solomon (RS) and
Bose, Chaudhari, and Hocquenghem (BCH) codes, are commonly used in block
encoding due to their robustness in correcting burst errors.
Convolutional Encoding
Convolutional encoding generates a sequence of coded bits from a
continuous stream of information bits, taking into account the current
and previous bits. This technique is characterized by its use of shift
registers and exclusive OR adders, which determine the encoded output
based on a predefined constraint length.
The choice between block and convolutional encoding depends on the
expected error patterns at the demodulator output. Convolutional
encoding is effective under stable propagation conditions and Gaussian
noise, where errors occur randomly. Conversely, block encoding is
preferred in fading conditions where errors occur in bursts.
Channel Decoding
Forward error correction (FEC) at the decoder involves utilizing the
redundancy introduced during encoding to detect and correct errors.
Various decoding methods are available for block and convolutional
codes.
Decoding Block Cyclic Codes
For block cyclic codes, a common decoding method involves calculating
and processing syndromes, which result from dividing the received block
by the generating polynomial. If the transmission is error-free, the
syndrome is zero.
Decoding Convolutional Codes: The Viterbi Algorithm
Convolutional codes are a type of error-correcting code used in
digital communications to improve the reliability of data transmission
over noisy channels. Decoding these codes involves determining the most
likely sequence of transmitted data bits given the received noisy
signal. The Viterbi algorithm is the most widely used method for
decoding convolutional codes, providing optimal performance in terms of
error correction.
Understanding Convolutional Codes
In a convolutional coding system:
Input Data Stream (u): A stream of data bits to be transmitted.
Encoded Output (v): A stream of encoded bits, where
each set of input bits is transformed into a set of output bits using a
convolutional encoder. The relationship between input and output bits
is determined by the code rate (R_c), which is the ratio of input bits
to output bits (e.g., R_c = 1/2 means each input bit is transformed into
two output bits).
The convolutional encoder introduces redundancy, allowing the decoder
to detect and correct errors that occur during transmission.
The Viterbi Algorithm for Decoding
The Viterbi algorithm is a maximum likelihood decoding algorithm that
operates by finding the most likely sequence of encoded bits that could
have generated the received noisy signal. It does so by examining all
possible paths through a trellis diagram, which represents the state
transitions of the convolutional encoder.
Trellis Diagram: The trellis diagram is a graphical
representation of the state transitions of the convolutional encoder.
Each state represents a possible memory configuration of the encoder,
and transitions between states correspond to the encoding of input bits.
Path Metric: The Viterbi algorithm calculates a
path metric for each possible path through the trellis, which is a
measure of how closely the received signal matches the expected signal
for that path. The path with the lowest metric (least errors) is chosen
as the most likely transmitted sequence.
Survivor Path: At each step, the algorithm retains
only the most likely path (survivor path) leading to each state. This
significantly reduces the complexity of the decoding process by
eliminating less likely paths.
Bit Error Probability (BEP)
Before Decoding (BEP_in): The bit error probability
at the decoder input (BEP_in) reflects the likelihood that a bit
received over the noisy channel is incorrect. This is influenced by the
channel conditions and the noise level.
After Decoding (BEP_out): After the Viterbi
algorithm has decoded the received signal, the bit error probability at
the output (BEP_out) is significantly reduced. This reduction occurs
because the algorithm corrects many of the errors introduced during
transmission by selecting the most likely transmitted sequence.
Key Steps in the Viterbi Decoding Process
Initialization: Set the initial path metric for the starting state (usually the all-zeros state) to zero, and all other states to infinity.
Recursion: For each received symbol, update the
path metrics for all possible states in the trellis by considering the
metrics of paths leading to those states. Retain only the most likely
path to each state.
Termination: Once all received symbols have been
processed, trace back through the trellis along the survivor path to
reconstruct the most likely transmitted sequence.
Output: The output sequence is the decoded data, with errors corrected based on the maximum likelihood path.
Benefits of the Viterbi Algorithm
Optimal Error Correction: The Viterbi algorithm
provides optimal decoding in terms of minimizing the bit error rate,
making it highly effective for communication systems requiring reliable
data transmission.
Widely Used: It is widely used in various
communication standards, including satellite communications, mobile
networks, and wireless LANs, due to its effectiveness and feasibility of
implementation.
Reduced BEP: The algorithm’s ability to correct
errors results in a significant reduction in the bit error probability
(BEP_out) compared to the input BEP, improving the overall reliability
of the communication system.
In summary, the Viterbi algorithm plays a crucial role in decoding
convolutional codes, enabling reliable communication over noisy channels
by effectively reducing the bit error rate through optimal error
correction.
Energy per Bit
The bit error probability is typically expressed as a function of Eb/N0, where Eb
represents the energy per information bit; that is, the amount of power
accumulated from the carrier over the duration of the considered
information bit. As the carrier power is C, and the duration of the
information bit is Tb = 1/ Rb, where Rb is the information bit rate,
then Eb is equal to C/Rb. This relationship is crucial in determining
the required signal power for a given error rate. The decoding gain Gcod is defined as the difference in decibels (dB) between the required values of EbN0 with and without coding for the same bit error probability.
Concatenated Encoding
To further enhance error correction capabilities, block encoding and
convolutional encoding can be combined in a concatenated encoding
scheme. This approach involves an outer block encoder followed by an
inner convolutional encoder. At the receiver, the inner decoder first
corrects errors, and the outer decoder subsequently corrects any
residual errors.
The outer decoder is able to correct the occasional bursts of errors
generated by the inner decoder’s decoding algorithm, which produces such
bursts of errors whenever the number of errors in the incoming bit
stream oversteps the correcting capability of the algorithm. The
performance of concatenated encoding is improved while using simple
outer coders by implementing interleaving and deinterleaving between the
outer and inner coders.
Concatenated encoding is employed in standards such as DVB-S and
DVB-S2. For instance, DVB-S uses an RS (204, 188) outer block encoder
and a convolutional inner encoder with varying code rates. DVB-S2
enhances this by incorporating BCH and LDPC codes for the outer and
inner encoding stages, respectively, achieving performance close to the
Shannon limit.
Combining Modulation and Error Correction: Coded Modulation
Coded modulation is a technique used in digital communications that combines two important processes: modulation and error correction coding. Let’s break down these concepts in simpler terms.
Modulation and Error Correction Coding
Modulation: This is the process of converting
digital information (bits) into a signal that can be transmitted over a
communication channel, such as a satellite link. Different modulation
schemes (like QPSK, 8-PSK, and 16-QAM) represent data using different
patterns of signal changes.
Error Correction Coding (ECC): This adds extra bits
to the original data to help detect and correct errors that might occur
during transmission. These extra bits increase the overall bit rate,
meaning more bandwidth is needed.
Traditionally, these two processes are done separately. However, this
separate approach can lead to inefficiencies, especially when dealing
with high data rates and limited bandwidth.
Coded modulation integrates modulation and error correction into a single process. Here’s how it works:
Integrated Approach: Instead of adding redundant
bits separately, coded modulation expands the set of signal patterns
(called the alphabet) used in modulation.
Larger Alphabet: For example, instead of using a
simple 4-symbol set (like in QPSK), coded modulation might use an
8-symbol set (like in 8-PSK) or even larger. This means more bits can be
transmitted in each symbol duration.
Efficient Use of Bandwidth: By using a larger set
of symbols, coded modulation can transmit more information without
significantly increasing the required bandwidth.
Benefits of Coded Modulation
Improved Error Performance: Coded modulation
reduces the energy per bit needed to achieve a certain error rate. For
example, coded 8-PSK can perform significantly better (up to 6 dB gain)
than uncoded QPSK for the same spectral efficiency.
Spectral Efficiency: Although coded modulation may
have slightly less spectral efficiency than the pure higher-order
modulations (like 16-QAM), it achieves better overall performance in
terms of error rates.
Key Concepts in Coded Modulation
Symbol Duration (Ts): The time period during which each symbol is transmitted.
Free Distance (dfree): A measure of the minimum
distance between sequences of symbols in the coded modulation scheme. A
larger dfree means lower error probability.
Asymptotic Coding Gain (Gcod(∞)): The improvement
in error performance as the signal-to-noise ratio becomes very high.
It’s a measure of how much better the coded modulation performs compared
to uncoded modulation.
Types of Coded Modulation
Trellis Coded Modulation (TCM): Uses convolutional
encoding, which means the encoded output depends on the current and
previous input bits, forming a “trellis” structure.
Block Coded Modulation (BCM): Uses block encoding, where data is encoded in fixed-size blocks.
Trellis-Coded Modulation (TCM) for 8-PSK
Trellis-Coded Modulation (TCM) is an advanced technique that combines
modulation and coding to enhance the error performance of communication
systems, particularly over noisy channels such as satellite links. When
using an 8-PSK (8-Phase Shift Keying) scheme, each symbol represents 3
bits of data, enabling efficient use of bandwidth. The goal of TCM is to
maximize the minimum distance between possible transmitted signals
thereby reducing the probability of errors.
Set partitioning is a key step in TCM where the set of 8-PSK symbols
is divided into smaller subsets. This partitioning is done in a way that
maximizes the distance between points within each subset, which is
crucial for minimizing errors. Each subset is associated with different
paths in the trellis diagram. The partitioning is done hierarchically in
multiple levels, with each level representing a finer subdivision of
the symbol set, ultimately leading to a structure that facilitates
effective error correction.
A trellis diagram visually represents the state transitions of the
TCM encoder over time. Each state in the trellis corresponds to a
specific condition of the encoder’s memory elements. The diagram helps
in understanding how the encoder processes input bits and maps them to
output symbols while maintaining a memory of past states, which is
essential for the coding process.
The theoretical maximum spectral efficiency of 8-PSK is 3 bits/s/Hz.
However, with TCM, the effective spectral efficiency is 2 bits/s/Hz due
to the inclusion of coding. Despite this, the TCM scheme offers
significant power savings by providing a coding gain. This gain is
achieved by requiring less transmitted power to maintain the same level
of error performance as compared to an uncoded scheme.
The typical configuration of a TCM encoder involves encoding some of
the input bits using a binary convolutional encoder, while other bits
are left uncoded. This hybrid approach balances error protection and
complexity. The encoded bits provide robust error correction, while the
uncoded bits allow for efficient use of bandwidth. This structure
ensures that the most critical bits are better protected against errors,
enhancing the overall reliability of the communication system.
In summary, TCM using 8-PSK modulation improves the reliability and
efficiency of data transmission over satellite channels by integrating
modulation and coding. The set partitioning, trellis diagram, and
strategic encoding provide robust error correction while maintaining
high spectral efficiency, making TCM a powerful technique for
communication systems.
Optimizing for Constellation Dynamics
The choice of coding scheme depends on various factors specific to the constellation design:
Orbital Altitude: Low
Earth Orbit (LEO) constellations experience rapid Doppler shifts,
favoring convolutional codes. Geostationary Earth Orbit (GEO)
constellations have less severe Doppler effects, making turbo codes a
viable option.
Data Rates: Higher data
rates demand more complex coding schemes for robust error correction.
However, these come at the expense of increased decoding complexity, a
constraint for mobile user terminals with limited processing power.
Satellite constellations, comprising multiple satellites in low Earth
orbit (LEO), medium Earth orbit (MEO), or geostationary orbit (GEO),
demand robust and efficient channel coding techniques to maintain
reliable communication links.
Low Earth Orbit (LEO) Satellites
LEO satellites, due to their lower altitude, experience rapid changes
in propagation conditions and frequent handovers between satellites.
Channel coding in LEO constellations must be capable of handling burst
errors and varying signal quality. Concatenated encoding schemes,
particularly those combining RS and convolutional codes, are well-suited
for these conditions.
Medium Earth Orbit (MEO) Satellites
MEO satellites operate at higher altitudes than LEO satellites,
offering longer communication windows and more stable propagation
conditions. However, they still encounter significant signal degradation
due to distance and atmospheric effects. Block encoding techniques,
such as RS and BCH codes, provide robust error correction capabilities
for MEO satellite communication.
Geostationary Orbit (GEO) Satellites
GEO satellites maintain a fixed position relative to the Earth’s
surface, providing consistent and stable communication links. The
primary challenge for GEO satellites is mitigating the impact of
Gaussian noise and occasional signal fading. Convolutional encoding,
coupled with advanced decoding algorithms like the Viterbi algorithm, is
highly effective in this scenario.
Emerging Techniques
The field of channel coding is
constantly evolving. Here are some promising techniques for future
mobile satellite constellations:
1. Low-Density Parity-Check (LDPC) Codes:
Concept: Unlike
traditional error correcting codes with dense parity-check matrices
(lots of 1s), LDPC codes use sparse matrices with a low density of 1s.
This sparsity allows for efficient decoding algorithms.
Decoding Power: LDPC
codes achieve near-capacity performance, meaning they can correct errors
up to the theoretical limit imposed by channel noise.
Decoding Algorithms:
Iterative decoding algorithms like belief propagation are used. These
algorithms work by passing messages between variable nodes (data bits)
and check nodes (parity checks) in the LDPC code’s graphical
representation (Tanner graph). With each iteration, the messages get
refined, leading to improved error correction.
2. Iterative Decoding:
Traditional vs. Iterative:
Traditional decoding approaches often involve a single decoding pass.
Iterative decoding, on the other hand, performs multiple decoding
passes, progressively improving the decoded data.
Combining Multiple Codes:
This technique allows for the joint decoding of multiple codes applied
to the data. For example, an LDPC code could be combined with a
convolutional code.
Improved Performance: By
iteratively decoding these combined codes, the decoder can leverage the
strengths of each code, potentially achieving superior error correction
compared to single-code decoding.
3. Network Coding:
Beyond Traditional Coding:
Network coding breaks away from the paradigm of transmitting data
packets unchanged. Instead, it strategically combines information
packets at different network nodes.
Exploiting Network Topology:
Network coding utilizes the network’s structure to create redundant
information at various nodes. This redundancy can then be used to
reconstruct lost data packets even if some transmissions are corrupted.
Enhanced Reliability: In
mobile satellite networks, where channel effects can be severe, network
coding offers a way to improve overall network reliability by creating
multiple paths for data to reach its destination.
These emerging techniques offer exciting
possibilities for future mobile satellite constellations. LDPC codes
with their efficient decoding and near-capacity performance, iterative
decoding for potentially superior error correction, and network coding
for enhanced reliability through network-aware data manipulation, all
hold promise in creating robust and efficient communication systems.
Recent Breakthroughs
While the core concepts of LDPC codes,
iterative decoding, and network coding remain at the forefront of
satellite channel coding, recent breakthroughs are pushing the
boundaries of performance and efficiency:
1. Tailored Code Construction for Specific Channel Conditions:
Traditionally, “one-size-fits-all” coding schemes were used. Recent research focuses on constructing LDPC codes specifically tailored to the expected channel conditions for a particular satellite constellation.
This can involve optimizing the code’s
parity-check matrix structure based on factors like Doppler shift and
path loss. By customizing the code to the channel, researchers are
achieving even better error correction performance.
2. Faster Decoding Algorithms with Hardware Acceleration:
LDPC code decoding, while powerful, can
be computationally intensive for high data rates. Recent breakthroughs
involve developing faster decoding algorithms with hardware acceleration.
This can involve utilizing specialized
hardware like Field-Programmable Gate Arrays (FPGAs) or
Application-Specific Integrated Circuits (ASICs) optimized for LDPC
decoding. This hardware acceleration allows for real-time processing of
high-bandwidth data streams from satellites.
3. Integration with Modulation and Forward Error Correction (FEC) Schemes:
Channel coding often works in
conjunction with modulation techniques and Forward Error Correction
(FEC) schemes. Recent research explores jointly optimizing channel coding, modulation, and FEC for satellite communication.
By considering these elements as a
unified system, researchers are achieving significant improvements in
overall communication efficiency and reliability. This co-design
approach can unlock new possibilities for maximizing data throughput
while minimizing errors.
4. Machine Learning-assisted Decoding for Dynamic Channel Adaptation:
Satellite channel conditions can be
dynamic, and static coding schemes might not always be optimal. Recent
advancements involve exploring machine learning (ML) techniques for adaptive decoding.
In this approach, an ML model analyzes
real-time channel information and adjusts the decoding process
accordingly. This allows for dynamic adaptation to changing channel
conditions, further enhancing the robustness of communication.
These breakthroughs showcase the
continuous evolution of satellite channel coding. By tailoring codes,
accelerating decoding, and integrating with other communication elements
using cutting-edge techniques, researchers are paving the way for a
future of high-performance and reliable satellite communication.
Conclusion
Channel coding is indispensable in satellite constellations,
providing the necessary error correction capabilities to ensure reliable
communication. By incorporating advanced encoding techniques such as
block and convolutional encoding, along with concatenated encoding
schemes, satellite systems can achieve robust performance even in
challenging environments.
These emerging techniques offer exciting possibilities for future
mobile satellite constellations. LDPC codes with their efficient
decoding and near-capacity performance, iterative decoding for
potentially superior error correction, and network coding for enhanced
reliability through network-aware data manipulation, all hold promise in
creating robust and efficient communication systems. By tailoring
codes, accelerating decoding, and integrating with other communication
elements using cutting-edge techniques, researchers are paving the way
for a future of high-performance and reliable satellite communication.
As satellite technology continues to advance, the principles and
applications of channel coding will remain central to the development of
efficient and resilient communication systems.