 |
| Training Dataset samples: First row: class name; second row: number of images per class; the remaining corresponding rows are the sample images from that particular class. |
Underwater SONAR Image Classification and Analysis using LIME-based Explainable Artificial Intelligence
Computer Science > Computer Vision and Pattern Recognition
Abstract: Deep learning techniques have revolutionized image classification by mimicking human cognition and automating complex decision-making processes. However, the deployment of AI systems in the wild, especially in high-security domains such as defence, is curbed by the lack of explainability of the model.
To this end, eXplainable AI (XAI) is an emerging area of research that is intended to explore the unexplained hidden black box nature of deep neural networks. This paper explores the application of the eXplainable Artificial Intelligence (XAI) tool to interpret the underwater image classification results, one of the first works in the domain to the best of our knowledge.
Our study delves into the realm of SONAR image classification using a custom dataset derived from diverse sources, including the Seabed Objects KLSG dataset, the camera SONAR dataset, the mine SONAR images dataset, and the SCTD dataset. An extensive analysis of transfer learning techniques for image classification using benchmark Convolutional Neural Network (CNN) architectures such as VGG16, ResNet50, InceptionV3, DenseNet121, etc. is carried out.
On top of this classification model, a post-hoc XAI technique, viz. Local Interpretable Model-Agnostic Explanations (LIME) are incorporated to provide transparent justifications for the model's decisions by perturbing input data locally to see how predictions change. Furthermore, Submodular Picks LIME (SP-LIME) a version of LIME particular to images, that perturbs the image based on the submodular picks is also extensively studied. To this end, two submodular optimization algorithms i.e. Quickshift and Simple Linear Iterative Clustering (SLIC) are leveraged towards submodular picks. The extensive analysis of XAI techniques highlights interpretability of the results in a more human-compliant way, thus boosting our confidence and reliability.
Summary
Classifying underwater objects from sonar imaging is a key task for naval mine warfare as well as marine salvage. Using AI and Machine Learning for this task to date has been environmentally specific and required taking the results on faith. Here is a summary of the key points from the research paper by researchers at SRM University, Chennai, India on underwater SONAR image classification using transfer learning and explainable AI:
Key objectives:
- - Develop effective deep learning methods for classifying underwater acoustic images
- - Create a custom dataset by combining multiple public SONAR datasets
- - Apply transfer learning using pre-trained CNN models
- - Incorporate explainable AI techniques to interpret model predictions
Methodology:
- - Created a custom dataset with 2989 images across 6 classes (fish, human, mine, plane, seafloor, ship)
- - Evaluated multiple CNN architectures (VGG16/19, ResNet50, InceptionV3, DenseNet121/201, etc.)
- - Applied transfer learning by fine-tuning pre-trained models on the custom dataset
- - Tested different sampling strategies (random vs stratified) and data balancing techniques
- - Incorporated LIME and SP-LIME explainers to interpret model predictions
Key results:
- - Best performing model: DenseNet121 with 98.21% accuracy
- - Stratified sampling on balanced data gave best results
- - SP-LIME provided efficient and interpretable explanations compared to LIME
- - Explanations highlighted relevant image regions for classification decisions
Conclusions:
- - Transfer learning with pre-trained CNNs effective for SONAR image classification
- - Careful dataset balancing and sampling crucial for handling class imbalance
- - Explainable AI techniques like SP-LIME improve model interpretability and user trust
- - Future work: Enhance image quality, expand dataset, refine explainer masking
The paper demonstrates an effective pipeline for underwater SONAR image classification combining transfer learning, data balancing, and explainable AI techniques. The approach shows promise for enhancing automated underwater image analysis capabilities.
SP-LIME
SP-LIME (Submodular Pick LIME) is a variation of LIME (Local Interpretable Model-Agnostic Explanations) specifically designed for image classification tasks. Here's an overview of how SP-LIME works:
1. Superpixel segmentation:
- Instead of perturbing individual pixels, SP-LIME divides the image into superpixels - contiguous patches of similar pixels.
- The paper mentions using algorithms like QuickShift or SLIC (Simple Linear Iterative Clustering) for this segmentation.
2. Instance selection:
- SP-LIME carefully selects representative instances (superpixels) for interpretation.
- This selection process uses submodular optimization to improve model clarity and reliability.
3. Perturbation:
- Selected superpixels are then perturbed (turned on or off) to create a diverse set of samples.
4. Prediction:
- The black-box model generates predictions for these perturbed samples.
5. Local approximation:
- SP-LIME creates a locally interpretable model around the prediction, similar to LIME.
6. Explanation generation:
- The interpretable model provides explanations for which superpixels were most influential in the classification decision.
Key advantages of SP-LIME:
- Computational efficiency: By working with superpixels instead of individual pixels, SP-LIME reduces computational overhead.
- Improved interpretability: Superpixels often correspond to more meaningful image segments, potentially leading to more intuitive explanations.
- Representative sampling: The submodular optimization helps ensure diverse and representative explanations.
The researchers found that SP-LIME offered comparable or better explanations than standard LIME, often with reduced computational time. They experimented with different numbers of features and samples to find optimal settings for their SONAR image classification task.
Authors
Article Text
Index Terms:
Imaging SONAR, Underwater object classification, Transfer learning, Explainable AI (XAI), Local Interpretable Model-Agnostic Explanation (LIME).I Introduction
Imaging SONAR produces a reflectivity estimate of a portion of the ocean bottom using sound waves, hence, it is widely used to communicate, navigate, measure distances, and find objects on or beneath the water’s surface [1]. In contrast to optical imaging, SONAR is preferred for underwater imagery because optical imaging systems rely on light conditions for imaging, but SONAR does not rely on ambient light. Therefore, it can operate effectively in low-light or even no-light conditions. Furthermore, SONAR can be used to identify the differences between the highlight and the shadow regions, which makes SONAR the best option for underwater surveillance and investigation whenever optical systems fail to do the job [2]. Developments in autonomous underwater vehicles (AUVs) and remotely operated vehicles (ROVs) have enabled the implementation of underwater acoustic imaging equipment within a versatile framework on which the SONAR imaging equipment is placed below the underwater vehicles.
Although AUVs can effectively collect data, they lack the capability to autonomously detect or categorize objects. Hence, it requires human assistance to manually review and categorize. For a naval base tasked with monitoring coastlines for potential threats such as enemy submarines, maritime monitoring has to be as quick as possible, but this multistage manual operation extends the response time and increases the threat of a foreign intruder and national security. In this regard, the automation of underwater image analysis on acoustic images can enhance the mission’s autonomy while also reducing time, cost, and damage.
Traditional machine learning algorithms, such as Support Vector Machines (SVM) [3] and decision trees [4], are employed for object recognition in SONAR images. However, the effectiveness of these shallow techniques is limited, yielding an accuracy of up to 92% [5], [6]. Later, deep learning algorithms like Convolutional Neural Networks (CNN) improved the accuracy by utilizing more computational resources, getting it to about 94.40% [7]. The utilisation of transfer learning, wherein a pre-trained model serves as the base model, further boosted the accuracy to 97.33% [8].
Nevertheless, to apply such Artificial Intelligence (AI) systems in real-world scenarios of high-security concerns i.e. military/ defence, certain limitations curb the application of deep learning (DL) systems in the wild. One big challenge is the lack of availability of big data. Additionally, to come up with promising practical solutions for such confidential data, it is quite essential to have the validation of the results by conclusive interpretable evidence. However, this is where most of the existing DL models fail since they act as a ‘black-box’ while predicting the results. In such circumstances, it is crucial to enhance the reliability, trustworthiness, and interpretability of any deep neural network (DNN) model so that humans based on their situational awareness, can make decisions that involve interpreting the predictions from the model [9]. This can help in detecting abnormalities, aiding in better decision-making, reducing false alarms, facilitating training, and maintaining transparency [10], [11]. To this end, Explainable Artificial Intelligence (XAI) is an emerging area of research in Machine learning that is intended towards exploring the unexplained hidden “black box” nature of deep neural networks [12].
In this study, we address the black-box nature of deep learning model by incorporating XAI tools for underwater sonar image classification. The proposed underwater XAI image classification pipeline consists of two stages: First, the performance of various backbone classification models such as VGG16, VGG19 [13], ResNet50 [14], Inception V3 [15], DenseNet121, DenseNet201 [16], MobileNetV2 [17], Xception [18], InceptionResNetV2 [19], NASNetLarge, and NASNetMobile [20] are analysed via Transfer learning technique. The significance of sampling techniques (random vs. stratified) as well as data-balancing strategies (oversampling vs. undersampling) are also studied to see their impact on model performance.
Second, two popular explainable AI tools i.e. Local Interpretable Model-Agnostic Explanation (LIME) and submodular Picks LIME (SP-LIME) are employed to interpret the model decisions in a human-complaint manner. LIME and SP-LIME are perturbation-based techniques, suitable for most data types and images, respectively [21]. Two different sub-modular optimization algorithms viz. quickshift [22] and Simple Linear Iterative Clustering (SLIC) [23] are leveraged towards perturbing super-pixels in SP-LIME. Extensive analysis of the aforementioned XAI models are carried out to comprehend the model predictions, traits of the explainer predictions, impact of the hyperparameters on the explainer models and state-of-the-art comparisons. To the best of our knowledge, the literature on XAI for SONAR imagery analysis systems is scarce, making our model one of its early works in this field.
All the studies are carried out on a novel custom-made SONAR dataset curated in-house by consolidating various publicly available sonar datasets i.e. Seabed Objects KLSG [24], SONAR Common Target Detection Dataset (SCTD) [25], Camera SONAR dataset [26], and Mine SONAR images [27]. The key contributions of this paper are summarised as follows:
-
•
Development of a new tailored SONAR dataset by combining multiple publicly available SONAR image datasets.
-
•
A comparative study to assess how well various benchmark models perform with Transfer Learning for SONAR image classification.
-
•
Brief study on the significance of data sampling techniques and data-balancing schemes during model training.
-
•
Incorporating Explainable Artificial Intelligence (XAI) using LIME and SP-LIME, powerful tools offering visual explanations for underwater SONAR image classification results, one of its first kind to the best of our knowledge.
-
•
Extensive quantitative and qualitative analysis on the explanation from various models, the impact of sampling/data balancing strategies and hyperparameters and state-of-the-art comparison.
The forthcoming sections of this paper are organized as follows: The discussion of SONAR imaging and related work is presented in Section II. The development of the custom dataset used for training is described in Section III. Classification using pre-trained models and different Explainable Artificial Intelligence (XAI) methodologies, with a special focus on LIME and SP-LIME is described in Sections IV and V, respectively. The experimental findings are showcased in Section VI. Finally, discussion and conclusion are drawn in Section VII.
II Background and Related work
In this section, we briefly describe the working principle of SONAR imaging, the literature review, and the motivation behind this research work.
II-A SONAR working Principle
Sound navigation and ranging (SONAR) uses sound waves to capture the scene on the ocean floor. SONAR has two major components, the transmitter and receiver [28]. The transmitter transmits acoustic waves at a grazing angle to the bottom. These acoustic waves propagate through the water, bounce back by touching the objects or seafloor in their path, and then the receiver collects them, which illuminates a region on the seafloor. On the other hand, if there are no objects, then the back-scattered waves reach the transmitter, forming a uniform background. However, if objects are present on the seafloor, sound waves intercept and reflect from the objects and form a bright spot (commonly referred to as the “highlight”) at a distance equal to the range of the object [29]. By processing the signals, the SONAR system can generate detailed images, revealing the presence of underwater features such as reefs, wrecks, geological formations, and even enemy submarines, etc [30], [31].
II-B Underwater Object Classification
Different natural and artificial sounds, such as thermal noise, shipping noise, earthquakes, volcanic eruptions, and submarines, consistently disrupt the underwater acoustic environment. As a result, noise distorts and blurs the captured acoustic image [32]. Furthermore, acoustic images generated by SONAR have a lower resolution compared to optical images, and this resolution varies depending on the distance between the sensor and the detected object [33]. Despite these challenges, the progress made in the field of automatic object detection in SONAR imagery has been impressive, considering the relatively short duration of time. Earlier versions of underwater object detection and classification systems depended on a two-step detection process [34]. The first step involves collecting data, while in the second step, humans manually classify the collected data using predefined classes based on the available templates [35].
Langner et al. [36] utilised probabilistic neural networks and pattern-matching techniques based on clustering algorithms for automatic object detection and classification on side scan sonar images. Myers et al. [35] used template matching techniques to compare the target signature made from a simple acoustic model with a picture of the object that needs to be classified. H.Xu et al. [5] developed an Adaboost cascade classification model based on support vector machines (SVM) and achieved an accuracy of about 92%. The statistical approach [37] utilises the HS-LRT (highlight-shadow likelihood ratio test) to identify and emphasise areas with both shadow and highlight and subsequently, the region of interest is determined based on these shadow and highlight regions. Finally, an SVM is employed to detect the desired regions of interest.
In 2017, Mckay et al. [38] began utilising deep neural networks for SONAR image classification and also utilised transfer learning with the pre-trained model VGG16 and got an impressive accuracy of 93% on their custom side scan SONAR (SSS) dataset, and improved the accuracy further to 97.7% by including semisynthetic data generated from optical images. In 2018, Fuchs et al.[39] also utilized transfer learning for sonar image classification on aracati dataset with ResNet-50 as a backbone model and also did a comparative study with traditional machine learning approaches and achieved an accuracy of 88%. In 2020, Pannu et al. [40] utilised CNN for the classification of synthetic aperture radar (SAR) images, adeptly addressing data limitations through strategic augmentation. Transitioning to the M-STAR dataset, a deep learning-based approach achieves an impressive 80% accuracy, further boosted to 97% after meticulous balancing.
The comparative study by Du et al. [41] leveraged transfer learning for sonar image classification on the Seabed Objects KLSG dataset with the pre-trained models, namely AlexNet, VGG-16, GoogleNet, and ResNet101, which achieved a maximum accuracy of 94.81%. A study by Chungath et al. [8] also used transfer learning with a pre-trained model ResNet-50 to classify sonar images, achieved an impressive accuracy of 97.33%, and also showed the ways to train an image classification model with very few images using few-shot learning-based deep neural networks.
The comprehensive survey by Steiniger et al. [42], Domingos et al. [43], and Neupane et al. [44] explored past and current research involving deep learning for feature extraction, classification, detection, and segmentation of side scan and synthetic aperture SONAR imagery. Their work provides an insightful overview, serving as a cornerstone for understanding the dynamic applications of computer vision in this specialised underwater water domain.
II-C Explainable AI for SONAR Image Analysis
Most of the existing deep learning models are black boxes in nature whose predictions cannot be interpreted or understood by humans. The integration of explainable AI offers a transparent lens, providing nuanced visual explanations for the predictions [12]. It helps verify the performance of the deep learning models and also enhances user trust in those models. Nguyen et al. conducted a thorough comparison study that looked at how well explainable AI approaches such as LIME [21], SHAP [45], and Grad-CAM [46] work in a wide range of industrial settings with images [47]. Further, in other domains such as remote sensing, medicine, etc., XAI techniques are employed to verify the performance of deep learning models [48], [49]. Hassan et al. [50] used XAI on ultrasound and MRI images to classify prostate cancer in men. It is also used to study several respiratory disorders, including COVID-19, pneumonia, tuberculosis and skin lesion classification, to help doctors and clinicians come to strong and logical conclusions about deep learning models for detection and classification [48], [51]. Bennet et al. [52] created a neural-symbolic learning framework utilizing a CNN model with a latent space predictor to classify images. This framework gives information about the predicted image through an explainable latent space. Similarly, it is also used to explain the predictions of complex image captioning models, which visually depict the part of the image corresponding to a particular word in the caption through a visual mask [53].
The XAI programme [54] by DARPA underscores the ongoing efforts to enhance understanding, trust, and management of AI systems in the realm of defence. During the period of this programme, from 2015 to 2021, 11 XAI teams explored various machine learning approaches, i.e. tractable probabilistic models, causal models and explanation techniques leveraging state machines generated by reinforcement learning algorithms, Bayesian teaching, visual saliency maps and GAN dissection. [9]. Recent work on deep learning-based explainable target classification was studied by Pannu et al. [40]. In that work, the explainable AI tool LIME was leveraged to verify the performance of the synthetic aperture radar(SAR) image classification models.
There are very few research works with explainable AI for underwater SONAR imagery. To the best of our knowledge, the only known work in the domain is by [55], wherein Walker et al. developed a LIME-based XAI classification model for seafloor texture classification. Contrary to that work, our work addresses a reliable multi-class classification model by comparing different backbone models using transfer learning approach, and also by addressing data balancing and sampling strategies. Additionally, XAL techniques LIME and SP-LIME are incorporated to interpret the predictions of the top-performing model, in a human-compliant manner. Further, detailed quantitative and qualitative analyses on the impact of different hyper-parameters and computational constraints are also investigated in this work.
III Dataset for Learning
The foundation of any machine learning model is the training dataset. The publicly available SONAR dataset is limited mainly because SONAR, primarily utilized for defence applications, generates sensitive images that are kept confidential. Hence, initial studies in SONAR image classification employed private datasets of underwater acoustic images. Therefore, the gathering of data is vital in this scenario. This section details the experimental setup for acquiring and preparing the dataset for our studies.
III-A Data Acquisition
Acquiring data in an underwater environment necessitates coordinated efforts from multiple agencies and departments. The collection and labelling of a substantial amount of acoustic data for educational purposes is an expensive and time-consuming process. The confidential nature of the SONAR data results in sparse publicly available datasets with very few classes. Hence, we develop a new custom-made dataset by consolidating from four different publicly available open-source SONAR datasets, listed as follows:
-
1.
The primary dataset, referred to as Seabed Objects KLSG [24], comprises 1190 Side Scan SONAR images with a total of 385 images of shipwrecks, 36 images of drowning victims, 62 images of planes, 129 images of mines, and 578 images of the seafloor. The authors gathered these real SONAR images with the assistance of various commercial SONAR suppliers, including Lcocean [56], Klein Martin [57], and EdgeTech [58] accumulated over a period of ten years. A few classes with a total of 1171 images with a variety of dimensions, along with augmented images excluding mines, are accessible to the public through the link [59], with the purpose of supporting academic research in this particular domain.
-
2.
The second dataset named Sonar Common Target Detection Dataset (SCTD)1.0, was developed by Tsinghua University, Fudan University, Shanghai University, Hohai University, Jiangxi University of Technology, et al. [25], consists of a total of 596 images belonging to 3 classes. However, only 317 images, specifically 57 images of planes, 266 images of shipwrecks, and 34 images of drowning victims, each with different dimensions, are publicly accessible through the link [60].
-
3.
The Camera SONAR dataset [26], published by Kei Terayama et al. consists of 1334 underwater SONAR and camera photos of fishes with a dimension of 256x512. For this study, we will only be using the SONAR images.
-
4.
The dataset referred to Mine SONAR images provided in the Roboflow universe by Phan Quang Tuan comprises 167 SONAR images depicting mines with a dimension of 416x416 [27].
TABLE I: Dataset samples: First row: class name; second row: number of images per class; the remaining corresponding rows are the sample images from that particular class. ![[Uncaptioned image]](https://arxiv.org/html/2408.12837v1/x1.png)
By combining the aforementioned datasets, we curated our tailor-made dataset, which comprises a total of 2989 side scan SONAR images with 1334 fish images, 34 human images, 167 mine images, 123 plane images, 578 seafloor images, and 753 ship wreck images. Some sample images of our custom dataset, together with the image count for each label, are provided in Table I. All images in the dataset are obtained from the originally captured images without any preprocessing.
III-B Data Splitting
In a supervised learning environment, the objective is to construct a model that can accurately predict both the input sample and unseen samples. To evaluate the model’s performance, we divide the dataset into three mutually exclusive sets: train, validation, and test sets [61]. The model is developed using the training set, and then the developed models are fine-tuned using the validation set. Finally, the model’s performance is evaluated using the test dataset. Splitting the dataset has a major impact on the model’s quality by reducing both bias and variance [62]. A poor data split might lead to poor model performance, particularly in imbalanced datasets such as the one in the current case. This problem of data imbalance is common in many real-time applications where the number of data points in some classes is significantly higher than the other classes.
In our case, the majority class has 1334 images, and the minority class has only 34 images. In this situation, we should ensure that the train and test split have approximately equal numbers of samples in all the classes to maintain the class distribution intact. Otherwise, the model might overfit. Fig. 1 represents the class-wise distribution of our custom dataset. As seen, the fish class dominated with 44.6% of the dataset, while the human class represented only 1.1% of the dataset.

Figure 1: Class-wise distribution of the custom dataset. The class Fish contributes to around 45% of the dataset. The task of splitting the dataset for a deep learning network can be seen as a sampling problem, where the given dataset D containing N data samples needs to be partitioned into three mutually disjoint subsets, so we split the dataset to train, validation and test datasets. As per [61], if the dataset is imbalanced, simple random sampling cannot represent and maintain the class distribution for all the classes in the dataset, but statistical sampling-based data splitting approaches, such as stratified sampling [63], work better over random sampling because the core idea is to inspect the internal structure and distribution of each subclass of the dataset D and utilise this information to divide the dataset into a set of relatively homogeneous sample groups. In the current problem, both simple random sampling and stratified sampling are applied to the available dataset in the ratio of 70:15:15 among train, validation, and test splits, with simple random sampling randomly selecting images and stratified sampling selecting an image from a class with probability inversely proportional to the size of that class.
IV Methodology: Transfer Learning-Based Image Classification, Data Balancing and LIME-based Explanation
Training a deep neural network (DNN) from scratch with random weights demands substantial computational resources, extensive datasets, and considerable processing time [64]. In the other hand, Transfer learning trains a deep neural network (DNN) with less data and in less time all while getting better results [65]. This is beneficial when training on intensive image datasets, where the challenges associated with collecting and labelling data, given its cost and time-intensive nature, and privacy concerns surrounding real user data make its utilization increasingly challenging [66].
IV-A Transfer Learning
Transfer learning facilitates the rapid prototyping of new machine learning models by leveraging the weights and biases of pre-trained models from a source task [67]. This transfer of weights, essentially the transfer of knowledge, offers notable benefits [68] in several ways, not only in speeding up the convergence process during training but also in establishing a higher initial accuracy. This is especially advantageous when dealing with smaller datasets, demonstrating the efficiency and effectiveness of transfer learning [8].
Consider a domain, denoted as , with a feature space , and a marginal probability distribution , where is a set belonging to . Represented as , let be a task defined as , where is the label space and is the target predictive function. Suppose and as the source domain and corresponding learning task, and and as the target domain and target learning task, respectively. Let encompass the elements of the source domain data, where each represents a data point and denotes its class label. We want to make the target predictive function better for the learning task by using data from and , where or .
The transfer learning process begins with feature extraction from both the source domain and the target domain . Instead of initializing the network with random weights and biases, the idea is to initialize the weights from the source domain () and adjust the weights to the target domain . The target weights are optimized by backpropagation and gradient descent using the target data and are utilized it to predict the target learning task (). According to Chungath et al. [8] and Ribani et al. [65], this process involves making small changes to the network weights so that the model can understand high-level features that are unique to the dataset. This leads to better performance than direct training.

Figure 2: Overall architectural diagram of the proposed Underwater SONAR Image Classification model using Transfer learning and LIME-Explainable AI. Refer to the visual representation of Fig. 2 for the overall architecture of the proposed underwater SONAR image classification model using transfer learning and LIME. The model weights are pre-trained on ImageNet followed by fine-tuning on a target SONAR dataset. The target model is customized with three trainable layers, two dropouts, and a normalization layer. Additionally, an explainer (LIME/ SP-LIME) is incorporated on top of the classifier to provide explanations for the predictions made by the classification model.
IV-B Handling Data Imbalance
As explained in Section III-B, there exists a class imbalance problem in the dataset due to high variance in the number of samples per class. This issue is tackled through a dual strategy: Oversampling and Undersampling techniques [69] (refer Fig.3). Oversampling refers to the technique of adding more images to minority classes, whereas undersampling refers to the technique of randomly discarding some images from the majority class [70]. In our case, the majority classes are fishes, seafloor, and ships, while the minority classes are plane, human, and mine. To address the scarcity of plane, human, and mine images. We employ image augmentation techniques such as flipping, rotation, cropping, adjusting the brightness, contrast, random erasing, noise injection, mixing images, adding blur, sharpness, and colour jittering to generate synthetic images, as an instance of oversampling [71] (Refer to Fig.4). Conversely, to harmonise the abundance of ship, fish, and seafloor images, we randomly discard some with equal probabilities to balance image numbers for each class as an undersampling approach [72], [73]. The number of images before and after augmentation is mentioned in Table II.
Figure 3: Oversampling and Undersampling Illustration 
Figure 4: Augmented Images However, it’s crucial to note that Kotsiantis et al. [69] and Chawla et al. [74] cautioned against random oversampling due to its potential to heighten the risk of overfitting. This arises from the replication of exact copies of minority class examples, leading to the construction of seemingly accurate rules that may inadvertently be overly specific to individual replicated instances. Furthermore, in scenarios where the dataset is already sizeable but imbalanced, oversampling can introduce an additional computational burden. This underscores the importance of a nuanced approach to navigating the trade-offs associated with image oversampling techniques in the context of imbalanced datasets.
TABLE II: Number of Images/Class: First column: number of images before augmentation; & Second column: number of images after augmentation. Class Before Augmentation After Augmentation Fish 1334 498 Human 34 498 Mine 167 498 Plane 123 498 Seafloor 578 498 Ship 753 498 Total 2989 2988 IV-C eXplainable AI (XAI)
As explained earlier, deep learning models are opaque by nature; they only predict the target with a probability score. To interpret such ‘black-box’ models, Explainable AI (XAI) tools facilitates in gaining human reliance on AI technology. XAI addresses bias understanding and fairness by navigating the bias-variance trade-off in AI/ML models [75]. This promotes fairness and aids in mitigating bias during the justification or interpretation phase. Recognizing and managing bias is crucial for ethical AI practices, preventing the unjust distribution of benefits to any party. Thus, XAI enhances the transparency, fairness, and trustworthiness of AI systems, providing meaningful insights into the decision-making process for both experts and non-experts alike.
XAI Techniques can be broadly categorised into ‘transparent’ and ‘post-hoc’ methods [12]. Transparent approaches, like decision trees [76] and random forest [77], are naturally clear and easy to understand, which makes it easier to fully understand how the model works. These methods are well-suited for simpler models, offering direct insights into the decision-making process [78]. On the other hand, post-hoc approaches explain the models’ decision without altering or even knowing the inner works. Examples of such methods are Grad-CAM [79], SHAP (Shapley Additive Explanations) [45], and LIME (Local Interpretable Model-Agnostic Explanations) [21]. These techniques are particularly useful for understanding complex interactions in nonlinear or black-box models because they offer localised insights that improve transparency when dealing with complex data.
Traits of an Explainer: An explainer should be made considering the following characteristics: reliability, interpretability, and explainability based on psychological constructs as described in [10]. Reliability, also called fidelity in simple terms, means the explanation must be a reasonable representation of what the system does internally [21]. Interpretability refers to the ability to understand the concepts learned by a model [80], Explainability refers to the ability to justify the decisions made by a model and accurately describe the mechanism, or implementation, that led to an algorithm’s output [10]. Explainability is important for gaining the trust of users, providing insights into the causes of decisions, and auditing the model’s behaviour. Interpretability and explainability are two related but different concepts in the context of machine learning models, which is always debatable, as mentioned in [81].
IV-D Local interpretable Model-Agnostic Explanations (LIME) as an XAI tool
Local Interpretable Model-Agnostic Explanations (LIME) is a novel explanation technique used to explain the predictions made by any classifier in a manner that is both interpretable and faithful by training a locally interpretable model around the prediction [21]. It provides faithful explanations for predictions made by any classifier or regressor. This is achieved through the local approximation of the model, enabling the use of an interpretable model for enhanced understanding and interpretability [21]. In other words, LIME improves our model’s interpretability by tweaking input data locally to see how predictions change. Tweaking the data locally explains a single prediction for that instance, while global tweaking looks at the model’s behaviour across all data. The idea behind local explanations is to create an interpretable representation of an underlying model, making its decision-making process more understandable.
The mathematical formulation of the LIME explainer is detailed below: Let denote the model to be explained. is the original representation of the instance being explained. In a classification context, represents the probability (or a binary indicator) that the instance belongs to a specific class. Additionally, let be a proximity measure between an instance and , defining the locality around . Consider the loss function as a representation of how accurate the explanation function is at approximating within the locality defined by . The loss function for locally weighted squared loss is expressed as in (1)
(1) where is a dataset containing sampled instances , and represents the labels obtained from the original model. The term is a binary indicator of perturbed samples used to generate the original representation of instances. The function is selected to be a class of linear models, specifically . This formulation captures the essence of the locally weighted squared loss, emphasizing the importance of each sampled instance based on its proximity to the original instance in the feature space. The term in (1) functions as a locality measure and is computed as follows,
(2) where serves as the distance metric (e.g., cosine, euclidean distance) between the two instances and . The bandwidth of the kernel is a parameter that requires careful selection. By resolving the following optimization (3), LIME determines the explanation it produces, where represents the local behavior of the complex model around the instance .
(3) where represents the loss function measuring how well interpretable model approximates black-box model for a perturbed sample and is the complexity measure quantifying the simplicity of interpretable model.
To ensure both interpretability and reliability, the goal is to minimize the loss function , while restricting the complexity of the explanation to a level that is interpretable by humans. This is achieved by penalizing the explanation function if it becomes excessively complex in order to maintain the complexity of the surrogate model within acceptable limits.
IV-E Submodular Picks Local interpretable Model-Agnostic Explanations (SP-LIME) for images
The classifier may represent the image as a tensor with three colour channels per pixel, but an interpretable representation for our image classification task might be a binary vector indicating the “presence” or “absence” of a contiguous patch of similar pixels (a super-pixel). The process of explaining model predictions through LIME starts with the deliberate selection of an instance, or a group of instances (in our case, its super-pixels), that are worthy of interpretation. The selected instance’s features are then subtly altered to introduce perturbations, resulting in a diverse set of samples. Subsequently, the black-box model generates predictions for these altered samples.
Since perturbing the entire interpretable representation in our case would require more time and computational resources, we instead perturb a super pixel because certain regions of the images can identify a class; altering whether or not that region contributed to that class can produce the same results as altering the input pixels. Hence, another variant of LIME, viz. Submodular Picks Local interpretable Model-Agnostic Explanations (SP-LIME), which is customized for images. SP-LIME is a methodology designed to tackle the above challenges by employing submodular optimization [21]. This approach systematically identifies a collection of representative instances along with their corresponding explanations. Hence, the selection process is essential for improving the clarity and dependability of the model, particularly when there are constraints on computational resources. There are numerous algorithms based on clustering, watershed, energy optimization, and graph methods available for submodular optimisation, specifically for super-pixel segmentation [82]. In this study, we have selected the quickshift [22] and SLIC [23] algorithms to perform the task.
V Experimental Setup
In this section, we briefly describe the implementation details and the evaluation metrics used to evaluate the performance of the classification models.
V-A Implementation Details
In this study, we select prominent benchmark models, namely VGG16, VGG19 [13], ResNet50 [14], Inception V3 [15], DenseNet121, DenseNet201 [16], MobileNetV2 [17], Xception [18], InceptionResNetV2 [19], NASNetLarge, and NASNetMobile [20] to carry out transfer learning. To conduct a comparative analysis and evaluate their respective performances, both small models with low computational resource requirements and large models with high computational resource requirements are chosen.
Each pre-trained model is enhanced by adding a flattening layer to transform the multi-dimensional output into a one-dimensional vector,a dense layer comprising 1024 neurons with a relu activation function, a dropout rate of 0.25, one more dense layer comprising 512 neurons with a relu activation function, a batch normalisation layer, and again a 0.25 dropout to capture complex relationships within the data. Then, finally, a dense output layer with six neurons (tailored for our task) and a softmax activation function is added to enable multi-class classification, refer to Fig. 2 for a visual representation of the transfer learning process for image classification. The customised models are compiled using the adam optimizer with a low learning rate of 0.0001, ensuring fine-grained adjustments during training with categorical cross-entropy as the loss function to optimize the models for accurate multi-class classification. The number of epochs is not predetermined due to each model having its own parameters, hence early stopping is implemented with a patience of five.
The images in our custom dataset are in PNG and JPEG formats and exhibit a variety of dimensions. Hence, process the images by converting them into a NumPy array and reshaping them to a standard dimension of 224 by 224 pixels. Additionally, grayscale images are transformed into RGB format. To facilitate further analysis, we normalise the reshaped images, scaling pixel values from 0 to 1. For the purpose of classification, label encoding is employed, utilising one-hot encoding to represent the categorical labels effectively. The implementation is carried out on a machine equipped with an NVIDIA DGX A100 GPU, but we utilized only 25GB of RAM for training with Google’s TensorFlow framework.
V-B Evaluation Protocols
The performance of the developed models is assessed using well-established evaluation metrics, specifically precision, recall, F1-score, and accuracy, as described in [83], [84]. A brief description of each metric, along with its mathematical representation, is provided below:
Accuracy: It measures the proportion of correctly classified instances among the total instances. Accuracy is straightforward to interpret but can be misleading when classes are imbalanced.
(4) Precision: Precision focuses on the relevance of the positive predictions. It is the ratio of true positive predictions to the total number of positive predictions (true positives plus false positives).
(5) Recall: Recall, also known as sensitivity or true positive rate, measures the ability of a classifier to find all the relevant instances. Recall is crucial when missing a positive instance has severe consequences.
(6) F1-Score: The F1-Score is the harmonic mean of precision and recall. It provides a balance between precision and recall, taking both false positives and false negatives into account. F1-Score is particularly useful when classes are imbalanced, as it considers both false positives and false negatives equally.
(7) These metrics collectively provide insights into the performance of a classification model and are commonly used to evaluate the class-wise effectiveness of the model.
VI Experimental Results
In this section, the experimental results of our study are presented. A detailed classification analysis of the different CNN benchmark models using different sampling strategies (random vs. stratified) and data balancing schemes are provided in Section VI-A and Section VI-B. Further, the explainer predictions of XAI models LIME and SP-LIME are detailed, along with various ablation studies and state-of-the-art comparisons in Sections VI-C, VI-D, and VI-E, respectively.
VI-A Classification Model-Random Sampling
As mentioned in Section III-B , we divide the dataset into three segments—train, validation, and test using random sampling approach in which images from the dataset are chosen at random. The forthcoming section explains the outcomes of the unbalanced data vs balanced data-based classification.
VI-A1 Unbalanced Data
The random sampling approach on an unbalanced dataset leads to an inconsistent number of images per class in all the splits, which is also non-linear (Refer to Table III). The customised deep learning models, initialised with pre-trained weights, undergo rigorous training and evaluation to assess their effectiveness in our classification task. Fig. 5 and Table IV summarises the accuracy achieved with its epoch count by each model during the training process. In particular, VGG16 -95.75%, VGG19 - 95.31%, ResNet50 - 92.18%, Inception V3 - 96.65%, DenseNet121 - 97.32%, MobileNetV2 - 96.42%, Xception - 96.20%, InceptionResNetV2 exhibited a high accuracy of 97.76%, DenseNet201 - 97.09%, NASNetLarge - 95.75% and NASNetMobile of 96.20% are obtained on the test dataset.
TABLE III: Image counts in the train, validation, and test sets utilizing random sampling approach with unbalanced data. Class Train Set Validation Set Test Set Fish 959 191 184 Human 27 4 3 Mine 113 22 32 Plane 79 27 17 Seafloor 400 95 83 Ship 514 109 130 Total 2092 448 449 TABLE IV: Accuracy of Deep Learning Models developed utilizing random sampling approaches with unbalanced data. Model Epochs Training Accuracy (%) Validation Accuracy (%) Test Accuracy (%) VGG16 16 99.66 97.32 95.75 VGG19 6 98.42 96.88 95.31 ResNet50 22 87.47 93.09 92.18 Inception V3 8 99.80 97.99 96.65 DenseNet121 6 99.76 97.77 97.32 MobileNetV2 7 99.13 97.10 96.42 Xception 2 98.56 97.10 96.20 InceptionResNetV2 3 98.42 97.99 97.76 DenseNet201 8 99.85 98.21 97.09 NASNetLarge 7 99.66 96.88 95.75 NASNetMobile 5 99.28 96.65 96.20 
Figure 5: Accuracy of random sampling-based deep learning models using unbalanced data. TABLE V: Classification Report for Unbalanced Model using random sampling approach-InceptionResNetV2 Class Precision Recall F1-Score Accuracy Fish 1.00 1.00 1.00 1.00 Human 1.00 1.00 1.00 1.00 Mine 1.00 1.00 1.00 1.00 Plane 0.91 0.59 0.71 0.90 Seafloor 1.00 1.00 1.00 1.00 Ship 0.95 0.99 0.97 0.94 Although the accuracies are in an acceptable range, from the classification report (Refer to Table V and Fig. 7(a) it is observed that the test data is suboptimal for some classes such as plane, mine, and human. compared to majority classes of fish, shipwreck, and seafloor images. Such model testing with imbalanced data results in a biased model towards the majority class. To overcome this, data balancing technique i.e. using an equal number of images from each class to train the model to possibly balance the model, as mentioned in [69] is envisaged.
VI-A2 Balanced Data
The predictive ability of the models developed in the previous case scenario (unbalanced data) is undoubtedly questionable due to the limited number of test images in the minority class and the abundance of test images in the majority class. To address this issue and achieve data balance across different classes, we employ oversampling and undersampling techniques, as extensively discussed in Section IV-B. As a result, an equal number of 498 images per class is achieved. Further, random sampling approach is utilized to split the dataset into train, validate, and test sets. Hence the number of images per class will be balanced across the splits, as depicted in Table VI. The process of image classification using transfer learning is performed again using this newly balanced data. The accuracy achieved by each model during the training process with balanced data along with its epoch count is summarised in Table VII and in Fig. 6. These results highlight the performance of DenseNet201, which achieved an accuracy of 98.88%. The other backbone models achieved VGG16 - 95.53%, VGG19 - 95.08%, ResNet50 - 83.92%, Inception V3 - 97.32%, MobileNetV2 - 96.65%, Xception - 97.54%, InceptionResNetV2 - 96.42%, DenseNet121 - 98.43%, NASNetLarge - 97.32% and NASNetMobile of 96.87% accuracies, respectively on the test dataset.
TABLE VI: Image counts in the train, validation, and test sets utilizing random sampling approach with balanced data. Class Train Set Validation Set Test Set Fish 355 80 63 Human 341 83 74 Mine 357 69 72 Plane 346 77 75 Seafloor 355 67 76 Ship 337 72 89 Total 2091 448 449 TABLE VII: Accuracy of Deep Learning Models developed utilizing random sampling approaches with balanced data. Model Epochs Train Accuracy (%) Validation Accuracy (%) Test Accuracy (%) VGG16 14 99.13 96.21 95.53 VGG19 9 97.08 95.32 95.08 ResNet50 51 82.54 87.08 83.92 InceptionV3 7 99.66 95.99 97.32 DenseNet121 8 99.47 97.77 98.43 MobileNetV2 3 99.52 97.55 96.65 Xception 17 99.76 95.99 97.54 InceptionResNetV2 3 99.43 96.43 96.42 DenseNet201 12 99.85 97.32 98.88 NASNetLarge 4 99.52 97.32 97.32 NASNetMobile 6 99.56 96.88 96.87 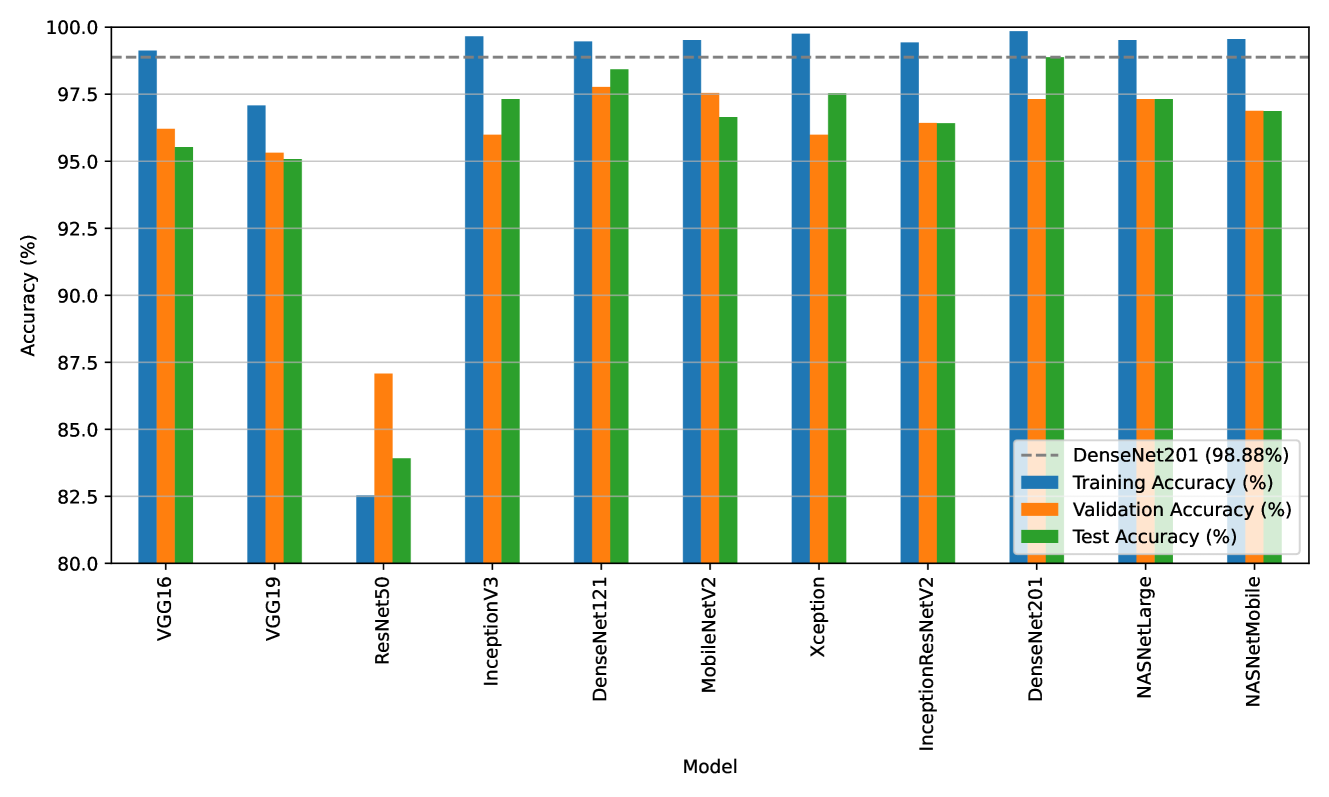
Figure 6: Accuracy of random sampling-based deep learning models using balanced data. TABLE VIII: Classification Report for Balanced Model using random sampling approach-DenseNet201. Class Precision Recall F1-Score Accuracy Fish 1.00 1.00 1.00 1.00 Human 0.97 0.96 0.97 0.98 Mine 1.00 1.00 1.00 1.00 Plane 0.97 0.95 0.96 0.97 Seafloor 0.97 1.00 0.99 0.97 Ship 0.95 0.97 0.96 0.94 Although there is a small drop in accuracy after balancing, the performance across all classes is consistent and well-balanced. Specifically, referring to Table V, the accuracy of the unbalanced model for the class labels ‘plane’ is 90%, Whereas, with the balanced model- DenseNet201 classification report, the accuracy has improved to 97%. However, some other class accuracies dropped slightly, e.g. human and seafloor (accuracies dropped from 100% to 98%). However, the model is generalized across all the classes (Refer Table VIII and Fig. 7(b)). This demonstrates a substantial improvement of balanced models on individual class performance compared to the performance of unbalanced models.

(a) InceptionResNetV2 - Unbalanced Model 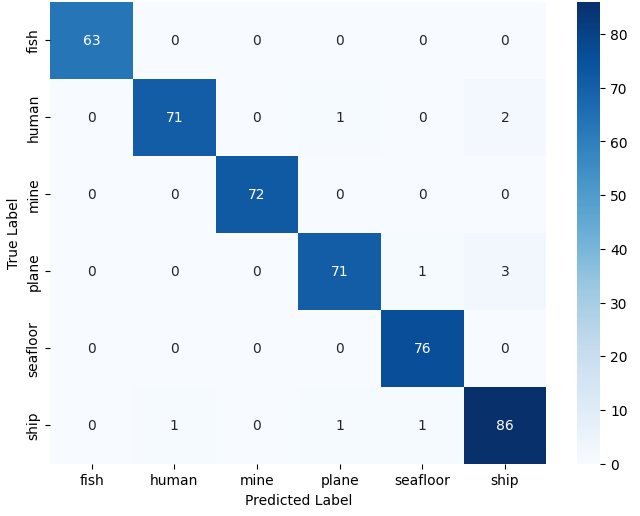
(b) DenseNet201 - Balanced Model Figure 7: Comparison of confusion matrices between balanced and unbalanced Model using random sampling approach. VI-B Classification Model-Stratified Sampling
The accuracy of the models developed in the previous Section VI-A leveraged random sampling techniques. As a result, the data sample representation from each class varies in both training and evaluation. To address this issue, an alternative sampling strategy stratified sampling techniques is employed [85]. As mentioned in Section III-B, we divide the dataset into three segments— train, validation, and test using stratified sampling techniques, which ensure that images from all classes are selected with equal probability. The outcomes of the unbalanced data vs balanced data are discussed below:
VI-B1 Unbalanced Data
The stratified sampling approach on an unbalanced dataset leads to a consistent number of images per class in all the splits, which is also linear (Refer to Table IX).
TABLE IX: Image counts in the train, validation, and test sets utilizing stratified sampling approach with unbalanced data. Class Train Set Validation Set Test Set Fish 934 200 200 Human 24 5 5 Mine 117 25 25 Plane 86 19 18 Seafloor 404 87 87 Ship 527 113 113 Total 2092 448 449 The customised deep learning models, initialised with pre-trained weights, undergo rigorous training and evaluation to assess their effectiveness in our classification task. As depicted in the Fig. 8, the following Table X summarises the accuracy achieved by each model, VGG16 achieved 96.65%, VGG19 - 96.65%, ResNet50 - 93.50%, Inception V3 - 97.10%, DenseNet121 - 98.44%, MobileNetV2, and DenseNet201 exhibited a accuracy of 97.55%, Xception - 97.32 %, InceptionResNetV2 - 97.99, NASNetMobile -97.32, and NASNetLarge - 96.21%.
TABLE X: Accuracy of Deep Learning Models developed utilizing stratified sampling approaches with unbalanced data. Model Epochs Train Accuracy (%) Validation Accuracy (%) Test Accuracy (%) VGG16 9 99.04 97.32 96.65 VGG19 6 98.90 97.09 96.65 ResNet50 18 84.32 93.52 93.50 Inception V3 12 99.76 97.76 97.10 DenseNet121 2 98.75 98.21 98.44 MobileNetV2 4 99.47 98.66 97.55 Xception 13 99.66 98.43 97.32 InceptionResNetV2 10 99.61 98.66 97.99 DenseNet201 8 99.61 98.66 97.55 NASNetLarge 6 99.71 98.43 97.32 NASNetMobile 3 98.80 97.99 96.21 
Figure 8: Accuracy of stratified sampling-based deep learning models using unbalanced data. Although the accuracy is improved compared to the models developed using random sampling approach, the performance of individual classes are still lower compared to the balanced models developed using random sampling techniques (Refer Fig. 10(a)). By comparing the class-wise accuracies in Table V and Table XI, we can observe a significant increase in individual class performance. The unbalanced model from the random sampling approach achieved an accuracy of 90% for the class ”plane”, whereas the counterpart result of the same unbalanced data through a stratified sampling approach achieves an accuracy of 93%, which is considerably higher but not equivalent to the accuracy of other classes.
TABLE XI: Classification Report for unbalanced Model using stratified sampling approach-DenseNet121. Class Precision Recall F1-Score Accuracy Fish 1.00 1.00 1.00 1.00 Human 1.00 0.60 0.75 1.00 Mine 1.00 1.00 1.00 1.00 Plane 0.93 0.78 0.85 0.93 Seafloor 1.00 0.99 0.99 1.00 Ship 0.94 0.99 0.97 0.94 VI-B2 Balanced Data
The stratified approach improved the overall accuracy, but the individual class accuracy is still lower. Hence, the predictive ability of the models developed above utilizing stratified sampling approach is still undoubtedly questionable due to the limited number of test images in the minority class and the abundance of test images in the majority class. To address this issue and to achieve data balance across different classes, oversampling and undersampling techniques are carried out, as extensively discussed in Section IV-B. As a result, 498 images per class is achieved, and stratified sampling approach is utilized in spitting the dataset into train, validate, and test sets. The number of images per class after splitting get balanced, as mentioned in Table XII.
TABLE XII: Image counts in the train, validation, and test sets utilizing stratified sampling approach with balanced data. Class Train Set Validation Set Test Set Fish 349 75 74 Human 348 75 75 Mine 348 75 75 Plane 348 75 75 Seafloor 349 74 75 Ship 349 75 74 Total 2091 448 449 The process of image classification using transfer learning is performed using this balanced data using stratified sampling. The accuracy achieved by each model during the training process with balanced data on the test dataset and validation dataset is summarised in Table XIII and depicted in the Fig. 9. These results highlight the performance of DenseNet121, which achieved an impressive accuracy of 98.21%, DenseNet201 - 97.55%, NASNetLarge - 97.10%, MobileNetV2 and InceptionResNetV2 - 96.65%, Xception - 95.76%, InceptionV3 and NASNetMobile - 95.66%. VGG19 - 94.87%, VGG16 - 94.87 and ResNet50 - 84.40%, all surpassing the 95% accuracy mark.
TABLE XIII: Accuracy of Deep Learning Models developed utilizing stratified sampling approaches with balanced data. Model Epochs Train Accuracy (%) Validation Accuracy (%) Test Accuracy (%) VGG16 8 98.08 96.65 94.87 VGG19 12 98.23 96.20 94.87 ResNet50 37 72.40 85.49 84.40 Inception V3 5 99.18 98.21 95.76 DenseNet121 15 99.76 99.33 98.21 MobileNetV2 2 98.51 97.76 96.65 Xception 3 98.94 97.99 95.99 InceptionResNetV2 12 99.42 98.21 96.65 DenseNet201 7 99.85 98.66 97.55 NASNetLarge 5 99.85 97.99 97.10 NASNetMobile 6 99.23 98.66 95.76 
Figure 9: Accuracy of stratified sampling-based deep learning models using balanced data. The classification report, as shown in Table XIV and the Fig. 10(b), indicates that the class-wise accuracy has improved. By using a stratified approach on balanced data, the accuracy for “human”, “plane” and “ship” has reached 100%, 98% and 97% respectively. This represents an improvement from the previous model’s accuracy developed using balanced data through random sampling techniques for “plane” (from 93% to 98%) and for “ship” (from 94% to 97%).
TABLE XIV: Classification Report for balanced Model using stratified sampling approach-DenseNet121. Class Precision Recall F1-Score Accuracy Fish 1.00 1.00 1.00 1.00 Human 1.00 1.00 1.00 1.00 Mine 1.00 1.00 1.00 1.00 Plane 0.99 0.97 0.98 0.98 Seafloor 1.00 0.99 0.99 1.00 Ship 0.97 1.00 0.99 0.97 
(a) DenseNet121 - Unbalanced Model 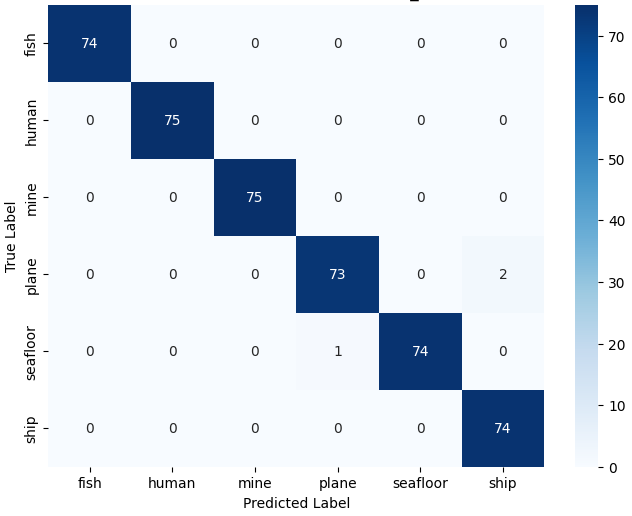
(b) DenseNet121 - Balanced Model Figure 10: Comparison of confusion matrices between balanced and unbalanced model using stratified sampling approach. These insights emphasize the critical role of choosing the correct sampling approach and balanced data along with well-suited, pre-trained models. Among the options considered, DenseNet121 from the stratified approach using balanced data stood out as the most fitting choice for our classification task, demonstrating outstanding validation accuracy of 99.33% and a test accuracy of 98.21%, hence it is considered the de-facto model for our following XAI study.
VI-C Explaining the predictions from the classifier using SP-LIME
As a result of various combinations of random vs. stratified sampling strategies as well as balanced and unbalanced approaches (as mentioned in previous Sections VI-A and VI-B), we developed altogether forty-four distinct classification models, with forty of them having an accuracy of more than 95%. We chose the model DenseNet121 with the highest accuracy and superior generalisation abilities for each class developed using stratified approach on balanced data and incorporated the post-hoc SP-LIME technique, a variation of LIME, to enhance explainability.
Although LIME can provide valuable insights, it is important to carefully choose which instances perturb, since perturbing all the pixels in the image demands more time and computation, hence selected instances are perturbed such as super-pixels, viz. SP-LIME. This is because users may not have the time or capacity to review a large number of explanations, as explained in Section IV-D.

Figure 11: Super-pixels from QuickShift Algorithm The hyper-parameters of the explainer is the number of features and the samples. Features refer to the characteristics or attributes of data points such as pixel values, colour channels, and texture information, whereas samples are individual data points or instances in the dataset. Ten features are taken into account, and 300 samples are used for the analysis with QuickShift [22] algorithm for submodular optimization, it considers features (such as pixel intensities) to identify regions of similar density. The quickShift algorithm with a kernel size of 2, a maximum distance of 100, and a ratio of 0.1 then groups samples (pixels) based on their proximity and density, produces 186 super-pixels, as illustrated in the Fig. 11. From the visual explanation in Fig. 12, for the top three predicted classes and their associated probabilities: ‘Plane’ with a probability of 1.00000, ‘Ship’ with 0.00000, and ‘Human’ with 0.00000, it is clear that the plane’s features, including the tail, head, and parts of the wings, are carefully considered for image classification. Conversely, the shadow region is disregarded, indicating that these areas do not contribute to the classification. The probabilities for all other classes are zero, hence the explainer does not mask any region and it points out that the explainer operation is solely focused on the classification model. This comparative analysis illuminates the nuanced performance and interpretability of SP-LIME explainer.

Figure 12: Explaining the prediction made by DenseNet121 neural network (Balanced Model) using SP-LIME. The top 3 classes predicted are ”Plane” (p = 0.100), ”Ship” (p = 0.000) and ”Human” (p = 0.000) The explainer process for the above model took 16.99 seconds for sampling, contributing to a total execution time of 149.88 seconds. To accommodate varying computational resource demands, we have the flexibility to reduce the number of super-pixels. The determination of the optimal number of features and perturbations is contingent upon the inherent complexity of the images under consideration. When appropriately tuned, it has the capacity to yield exceptional results within a reduced timeframe and with minimal computational overhead. This adaptability underscores the efficiency of SP-LIME in generating accurate and interpretable explanations for complex image data. The presented visual representations provide valuable insights into the explainer’s functioning, which is intricately tied to the underlying model predictions which underscores the significance of leveraging SP-LIME explainer as a tool that empowers users to make informed decisions based on a clearer understanding of model predictions through visual representations.
VI-D Ablation Study
In this section, various ablation studies such as comparing the performance of the explainer with a balanced and an unbalanced model, evaluating the impact of different hyper-parameters and assessing the computation time and performance for LIME and SP-LIME across different classes are carried out.
VI-D1 Explainer with balanced and unbalanced models
In this experiment, the impact of the SP-LIME explainer with sampling and data balancing strategies is analysed. Both the random and stratified sampling along with balanced vs unbalanced datasets using our top-performing model are studied. Table XV summarises the visual explanation along with the original image.
TABLE XV: SP-LIME with different models: First row: sampling techniques, second row: model’s balance, third-row predicted class: plane, and fourth-row predicted class: ship, and the corresponding visual explanation images from that particular class. ![[Uncaptioned image]](https://arxiv.org/html/2408.12837v1/x11.png)
Table XV, it can be observed that the balanced model from the stratified sampling approach provides the best visual explanation, with a focus on the area with the exact mask. Compared to the random sampling technique, stratified sampling outperformed in selecting the target object precisely. Similarly, it is seen that the unbalanced model from both approaches results in more shadow regions, compared to the balanced model. For the plane and ship prediction, it is clear that the mask from the stratified balanced model outperforms the other models in explaining the tail&wing and the relevant ship regions, respectively.
VI-D2 Hyper-parameter of the Explainer- Number of Features
This section tries to understand the impact of number of features as a hyperparameter towards LIME explanation. Since SP-LIME perturbs at the super-pixel level while LIME perturbs each pixel, we assess the computational time taken for each approach, to better understand the performances and computational requirements of LIME and SP-LIME. We test LIME and SP-LIME’s performance in a number of different parameter settings, specifically investigating the number of features, tweaking to 10, 25, 50, 100, 150, 200, 250, 300, 400, and 500. Although SP-LIME has its own hyper-parameters, we have considered the following parameters as fixed as follows: super-pixel algorithm: quickshift, kernel size: 2, max distance: 100, and ratio: 0.1.
The number of features denote the quantity of features or input variables that the explainer will perturb in order to produce a local explanation. The absence of a large class group, coupled with relatively low variability in the dataset, diminishes the computational expense sensitivity to changes in the number of features for both LIME and SP-LIME. Despite this, the choice of the feature count significantly influences the effectiveness of the explanations provided for the classification decisions (refer to Fig. 13) and Table XVI.
TABLE XVI: Comparison with 100 Samples on LIME & SP-LIME Number of Features Computation Time in Seconds LIME SP-LIME 10 5.98 5.20 25 6.75 6.09 50 6.61 5.87 100 6.38 7.03 400 6.87 7.21 500 5.87 7.09 
(a) 
(b) 
(c) 
(d) Figure 13: Comparison of LIME and SP-LIME explanations on varing number of features: (a) 10 features & 100 samples on LIME, (b) 10 features & 100 samples on SP-LIME, (c) 500 features & 100 samples on LIME, (d) 500 features & 100 samples on SP-LIME. From Table XVI, it can be observed that if more features are considered for both LIME and SP-LIME, then it may result in more computational time requirement spent calculating the mask. The comparative visualization analysis of LIME and SP-LIME by varying the number of features is given in Fig. 13. It can be observed that Fig. 13 (a) from LIME and Fig. 13 (b) from SP-LIME with 10 features outperform the rest (c) and (d) with 500 features. Further, SP-LIME takes less time to compute but gives a comparable explanation to LIME, which can be further tuned with some changes in parameters.
VI-D3 Hyper-parameter of the Explainer- Number of Samples
The number of samples represents the number of synthetic samples generated by the explainer for each perturbation. We fix the number of features to 10, vary the number of samples with values ranging from 100 to 1000, and analyse the performance of our XAI model. The computational time associated with each combination of parameters are shown in Table XVII.

(a) 
(b) Figure 14: Comparison of LIME and SP-LIME explanations on varing number of samples: (a) 10 features & 1000 samples on LIME, (b) 10 features & 1000 samples on SP-LIME. TABLE XVII: Comparison with 10 Features on LIME & SP-LIME. Number of Samples Computation Time in Seconds LIME SP-LIME 100 5.98 5.20 200 13.42 10.40 300 18.84 13.95 800 52.55 40.42 900 53.03 46.78 1000 66.83 52.70 From Table XVII, it can be observed that the number of samples also influences the explainer, which results in an increase in computation with an increase in the number of samples. From Fig. 14, it can be noted that the explanation from SP-LIME is better than LIME since the LIME captured more regions, which is of no interest with more computational resources and more time, but on the other hand, the SP-LIME masked the zone, which is very close to the region of interest. Depending on the dataset and the computational constraints available, a trade-off between the number of features and samples should be made for a better explanation. So we chose 10 features and 500 samples and applied them to both LIME and SP-LIME. The LIME explainer took 31.61 seconds. On the other hand, the SP-LIME explainer took 20 seconds and produced comparable results (refer to Fig. 15).

(a) 
(b) Figure 15: A Comparison of Effective Explanations from SP-LIME and LIME: (a) 10 features & 500 samples on LIME, (b) 10 features & 500 samples on SP-LIME. Without sacrificing the interpretability that LIME achieves, SP-LIME offers a faster runtime. The specified parameters for SP-LIME were crucial in achieving this efficiency for our dataset, demonstrating the effectiveness of the chosen configuration. This comparison provides valuable insights into the trade-offs between runtime and interpretability in the context of model explanation techniques.
VI-D4 SP-LIME and the corresponding Super-pixel Algorithm
The algorithm used to generate super-pixels also affects SP-LIME’s performance. So, we conducted a brief analysis on the performance of SP-LIME, with a specific focus on two distinct algorithms: quickshift [22] and SLIC [23] (Simple Linear Iterative Clustering). For the quickshift algorithm, the SP-LIME explainer took 20.00 seconds, with key parameters including a kernel size of 2, a maximum distance of 100, a ratio of 0.1, 10 selected features, and 500 samples. On the other hand, the SLIC algorithm took 20.47 seconds with similar parameter configurations. Notably, the findings highlight the computational efficiency and performance of SP-LIME (refer figure 16) when employing the quickshift algorithm in contrast to SLIC, shedding light on the nuanced trade-offs between computational resources and the quality of decision explanations.

(a) 
(b) Figure 16: Comparing explanations from distinct super-pixel algorithms on SP-LIME: (a) Quickshift, (b) SLIC (Simple Linear Iterative Clustering.) From Fig. 16, it can be noticed that both explanations are similar to each other, however, the explanation using quickshift with SP-LIME captured more regions in the target object that SLIC did not capture. The computational time difference between both algorithms is minimal, but for our dataset, Quickshift performs better.
VI-D5 Impact of explainer on different classes
The quality, variety, and veracity of the images used during training have a significant impact on the explainer’s effectiveness. Analysis of the classes: mine, fish, and human from the Fig. 17(a), Fig. 17(b), and Fig. 17(c) suggests that the classification model’s accuracy is compromised, evident in the inaccuracies of the generated masks that fail to align with the actual regions of interest.

(a) Explanation for Mine 
(b) Explanation for Fishes 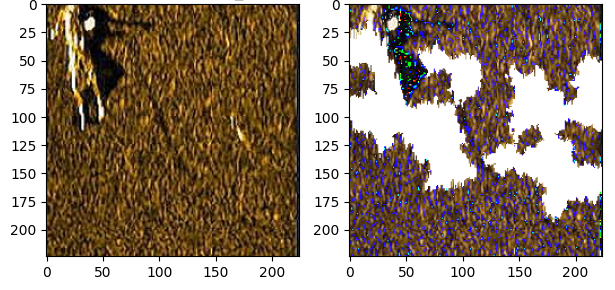
(c) Explanation for Human Figure 17: Inaccurate Explanations The explanation mask accuracy differs due to training data. The original “human” dataset had 34 images, and augmentation added 498 images to this dataset. However, this augmentation may have caused the images to differ, causing the model to learn patterns rather than accurately capture human objects’ intrinsic shapes. Hence, the model’s performance suffers, and the explainer struggles to provide clear explanations. For the ‘fish’ and ‘mine’ classes, the dataset is of poor quality with data limitations and similarity, so the model failed to provide meaningful explanations. On the other hand, for the classes plane, ship, and seafloor (refer Fig. 18(a), Fig. 18(b), and Fig. 18(c)), promising explanations are achieved due of the quality and quantity of images used for training. We envisage that image enhancement techniques such as SRGAN [86] and attention techniques could be employed to enhance image quality and to direct explainer towards the area of interest.

(a) Explanation for Seafloor 
(b) Explanation for Ship 
(c) Explanation for Plane Figure 18: Accurate Explanations VI-E State of the Art Comparison
To showcase the efficacy of our classification model, a thorough comparison was conducted with existing models, evaluating their respective accuracies. In underwater SONAR imagery, there are very few research works as follows, Divya et al. [87] employed ResNet50 and ensemble techniques on seabed KLSG data, achieving a notable accuracy of 90%. In a study by Najib et al. [88] on NAT III, a DCNN yielded an impressive accuracy of 98.44%. Wang et al. [89], utilizing AWCNN, achieved an accuracy of 86.90%. Nguyen et al. [33], working with CKI and TDI datasets, utilized GoogLeNet and attained an accuracy of 91.60%. Chungath et al. [8], combining seabed and custom datasets and employing ResNet34, reported an accuracy of 97.33%. Fernandes et al. [90] utilized a tailor-made CNN on a custom dataset, achieving a maximum accuracy of 99%. Luo et al. [7], using a shallow CNN with seabed sediment data, obtained an accuracy of 94.40%. Zhou et al. [91] employed SCTD and achieved an accuracy of 95.84 through IMDNet. The results, as illustrated in Table XVIII, unequivocally highlight the superior performance of our customised DenseNet121 model, positioning it at the forefront of the evaluated models with an accuracy of 98.21%.
TABLE XVIII: State of the Art (SOTA) Comparison - Image Classifier. Model Dataset Accuracy (%) ResNet50 [87] Seabed Objects KLSG 90.00 DCNN [88] Array Technology III (NAT III) 98.44 AWCNN [89] Custom Dataset 86.90 GoogleNet [33] CKI, TDI-2017 and TDI-2018 91.60 ResNet34 [8] Seabed + Custom Dataset 97.33 CNN [90] Custom Dataset 99.00 Shallow CNN [7] Seabed sediment 94.40 IMDNet [91] SCTD 95.84 VGG16 [41] Seabed Objects KLSG 94.81 ResNet50 [39] Aracati 88.00 DenseNet121 (Ours) Custom Dataset 98.21 TABLE XIX: State of the Art (SOTA) Comparison: Image Explainer. Existing Paper Dataset Explainer Explainable Systematic Analysis For Synthetic Aperture SONAR Imagery [55] Multi-site and Single-site LIME Deep learning-based explainable target classification for synthetic aperture radar images [40] MSTAR LIME LIME-Assisted Automatic Target Recognition with SAR Images: Towards Incremental Learning and Explainability [92] MSTAR LIME Underwater Sonar Image Classification and Analysis using LIME-based Explainable Artificial Intelligence Custom Dataset LIME and SP-LIME For the comparison of our explainer in our research paper, we reviewed three key papers that contribute to the field of explainable AI for synthetic aperture imagery, tabulated in Table XIX. In the field of SONAR imagery, Walker et al. [55] used LIME to learn about important features that play a part in improving performance and to learn how important it is to balance data for fine-tuning deep learning models in classifying SAS seafloor images. In 2023, Oveis et al. [92] conducted a study using LIME, for target recognition with synthetic radar images. Additionally, Pannu et al. [40] also utilized LIME for a similar purpose. Utilizing radar images, Pannu et al.’s (2020) study used LIME to perform target classification, Both studies utilized the MSTAR dataset. Since there are no specific metrics for explaining the model, the usefulness of these explainer models depends entirely on the user’s perspective. We utilized LIME to provide explanations for the predictions made by an underwater SONAR image classifier, thereby improving the trust and effectiveness of the black box model.
VII Conclusion and Future Works
In this study, our primary objective was to develop effective deep learning methodologies to tackle the inherent classification challenges associated with underwater acoustic images. Due to the limited availability of public datasets in this specialized domain, we curated a customized dataset by amalgamating data from multiple sources. This tailored dataset formation emerged as a crucial facet of our investigation. Our methodology centers around using a pre-trained deep neural network. We examined various backbone models, such as VGG16, VGG19, ResNet50, InceptionV3, DenseNet121, MobileNetV2, Xception, InceptionResNetV2, DenseNet201, NASNetLarge, and NASNetMobile. We applied both stratified and random sampling approaches, as well as on balanced and unbalanced datasets. Through a combination of different sampling strategies and data balancing techniques, we found that the best model was DenseNet121. We fine-tuned this powerful architecture to our specific task using the limited data at our disposal. The experimental results unequivocally demonstrated the efficacy of our transfer learning strategy, showcasing remarkable outcomes in the classification of underwater acoustic images. A noteworthy observation arising from our study was the potency of well-established sampling techniques in addressing challenges associated with imbalanced datasets. Rather than resorting to resource-intensive and intricate synthetic data generation methods, we illustrated the effectiveness of careful dataset balancing through sampling. This strategic approach significantly mitigated misclassifications, especially for classes characterized by a scarcity of samples. To enhance the interpretability of our classification model, we integrated the explainer models LIME and SP-LIME. This addition not only elevates the transparency of the model but also provides users with a clearer understanding of predictions. The incorporation of SP-LIME contributes to instilling confidence in users and facilitates more informed decision-making based on the model’s outputs. Notably, the SP-LIME mask reveals a slight misfit with the object of interest, even though the model is trained on class labels. To address this, our forthcoming work aims to refine the masking accuracy through the integration of image enhancement techniques such as Super-Resolution Generative Adversarial Networks (SRGAN) [86], focusing the Explainer on the region of interest, and the incorporation of richer and more diverse datasets with an expanded range of classes. This promising avenue holds the potential to further augment the model’s interpretability and predictive accuracy.
References
- [1]
-
•
- R. E. Hansen, “Synthetic aperture sonar technology review,” Marine Technology Society Journal, vol. 47, no. 5, pp. 117–127, 2013.
- [2]
- A. Fitzpatrick, A. Singhvi, and A. Arbabian, “An airborne sonar system for underwater remote sensing and imaging,” IEEE Access, vol. 8, pp. 189 945–189 959, 2020.
- [3]
- M. A. Hearst, S. T. Dumais, E. Osuna, J. Platt, and B. Scholkopf, “Support vector machines,” IEEE Intelligent Systems and their applications, vol. 13, no. 4, pp. 18–28, 1998.
- [4]
- J. R. Quinlan, “Simplifying decision trees,” International journal of man-machine studies, vol. 27, no. 3, pp. 221–234, 1987.
- [5]
- H. Xu and H. Yuan, “An svm-based adaboost cascade classifier for sonar image,” IEEE Access, vol. 8, pp. 115 857–115 864, 2020.
- [6]
- H. Febriawan, P. Helmholz, and I. Parnum, “Support vector machine and decision tree based classification of side-scan sonar mosaics using textural features,” International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences-ISPRS Archives, vol. 42, no. 2/W13, pp. 27–34, 2019.
- [7]
- X. Luo, X. Qin, Z. Wu, F. Yang, M. Wang, and J. Shang, “Sediment classification of small-size seabed acoustic images using convolutional neural networks,” IEEE Access, vol. 7, pp. 98 331–98 339, 2019.
- [8]
- T. T. Chungath, A. M. Nambiar, and A. Mittal, “Transfer learning and few-shot learning based deep neural network models for underwater sonar image classification with a few samples,” IEEE Journal of Oceanic Engineering, 2023.
- [9]
- D. Gunning, E. Vorm, Y. Wang, and M. Turek, “Darpa’s explainable ai (xai) program: A retrospective,” Authorea Preprints, 2021.
- [10]
- D. A. Broniatowski et al., “Psychological foundations of explainability and interpretability in artificial intelligence,” NIST, Tech. Rep, 2021.
- [11]
- M. A. Neerincx, J. van der Waa, F. Kaptein, and J. van Diggelen, “Using perceptual and cognitive explanations for enhanced human-agent team performance,” in Engineering Psychology and Cognitive Ergonomics: 15th International Conference, EPCE 2018, Held as Part of HCI International 2018, Las Vegas, NV, USA, July 15-20, 2018, Proceedings 15. Springer, 2018, pp. 204–214.
- [12]
- P. Gohel, P. Singh, and M. Mohanty, “Explainable ai: current status and future directions,” arXiv preprint arXiv:2107.07045, 2021.
- [13]
- K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [14]
- K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [15]
- C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826.
- [16]
- G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [17]
- M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4510–4520.
- [18]
- F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1251–1258.
- [19]
- C. Szegedy, S. Ioffe, V. Vanhoucke, and A. Alemi, “Inception-v4, inception-resnet and the impact of residual connections on learning,” in Proceedings of the AAAI conference on artificial intelligence, vol. 31, no. 1, 2017.
- [20]
- B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learning transferable architectures for scalable image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8697–8710.
- [21]
- M. T. Ribeiro, S. Singh, and C. Guestrin, “” why should i trust you?” explaining the predictions of any classifier,” in Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, 2016, pp. 1135–1144.
- [22]
- A. Vedaldi and S. Soatto, “Quick shift and kernel methods for mode seeking,” in Computer Vision–ECCV 2008: 10th European Conference on Computer Vision, Marseille, France, October 12-18, 2008, Proceedings, Part IV 10. Springer, 2008, pp. 705–718.
- [23]
- R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Süsstrunk, “Slic superpixels,” Tech. Rep., 2010.
- [24]
- G. Huo, Z. Wu, and J. Li, “Underwater object classification in sidescan sonar images using deep transfer learning and semisynthetic training data,” IEEE access, vol. 8, pp. 47 407–47 418, 2020.
- [25]
- P. Zhang, J. Tang, H. Zhong, M. Ning, D. Liu, and K. Wu, “Self-trained target detection of radar and sonar images using automatic deep learning,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2021.
- [26]
- K. Terayama, S. Kento, K. Mizuno, and K. Tsuda, “A dataset of camera and sonar images,” 4 2018. [Online]. Available: https://figshare.com/articles/dataset/A_dataset_of_camera_and_sonar_images/6193103
- [27]
- P. Q. Tuan, “Mine_sonar_images dataset,” https://universe.roboflow.com/phan-quang-tuan/mine_sonar_images, apr 2022, visited on 2023-11-20. [Online]. Available: https://universe.roboflow.com/phan-quang-tuan/mine_sonar_images
- [28]
- J. L. Sutton, “Underwater acoustic imaging,” Proceedings of the IEEE, vol. 67, no. 4, pp. 554–566, 1979.
- [29]
- A. Elfes, “Sonar-based real-world mapping and navigation,” IEEE Journal on Robotics and Automation, vol. 3, no. 3, pp. 249–265, 1987.
- [30]
- P. Blondel and B. J. Murton, Handbook of seafloor sonar imagery. Wiley Chichester, 1997, vol. 7.
- [31]
- M. P. Hayes and P. T. Gough, “Synthetic aperture sonar: A review of current status,” IEEE journal of oceanic engineering, vol. 34, no. 3, pp. 207–224, 2009.
- [32]
- X. Lurton, An introduction to underwater acoustics: principles and applications. Springer Science & Business Media, 2002.
- [33]
- H.-T. Nguyen, E.-H. Lee, and S. Lee, “Study on the classification performance of underwater sonar image classification based on convolutional neural networks for detecting a submerged human body,” Sensors, vol. 20, no. 1, p. 94, 2019.
- [34]
- S. Daniel, F. Le Léannec, C. Roux, B. Soliman, and E. P. Maillard, “Side-scan sonar image matching,” IEEE Journal of Oceanic Engineering, vol. 23, no. 3, pp. 245–259, 1998.
- [35]
- V. Myers and J. Fawcett, “A template matching procedure for automatic target recognition in synthetic aperture sonar imagery,” IEEE Signal Processing Letters, vol. 17, no. 7, pp. 683–686, 2010.
- [36]
- F. Langner, C. Knauer, W. Jans, and A. Ebert, “Side scan sonar image resolution and automatic object detection, classification and identification,” in OCEANS 2009-EUROPE. IEEE, 2009, pp. 1–8.
- [37]
- A. Abu and R. Diamant, “A statistically-based method for the detection of underwater objects in sonar imagery,” IEEE Sensors Journal, vol. 19, no. 16, pp. 6858–6871, 2019.
- [38]
- J. McKay, I. Gerg, V. Monga, and R. G. Raj, “What’s mine is yours: Pretrained cnns for limited training sonar atr,” in OCEANS 2017 - Anchorage, 2017, pp. 1–7.
- [39]
- L. R. Fuchs, A. Gällström, and J. Folkesson, “Object recognition in forward looking sonar images using transfer learning,” in 2018 IEEE/OES Autonomous Underwater Vehicle Workshop (AUV). IEEE, 2018, pp. 1–6.
- [40]
- H. S. Pannu, A. Malhi et al., “Deep learning-based explainable target classification for synthetic aperture radar images,” in 2020 13th International Conference on Human System Interaction (HSI). IEEE, 2020, pp. 34–39.
- [41]
- X. Du, Y. Sun, Y. Song, H. Sun, and L. Yang, “A comparative study of different cnn models and transfer learning effect for underwater object classification in side-scan sonar images,” Remote Sensing, vol. 15, no. 3, p. 593, 2023.
- [42]
- Y. Steiniger, D. Kraus, and T. Meisen, “Survey on deep learning based computer vision for sonar imagery,” Engineering Applications of Artificial Intelligence, vol. 114, p. 105157, 2022.
- [43]
- L. C. Domingos, P. E. Santos, P. S. Skelton, R. S. Brinkworth, and K. Sammut, “A survey of underwater acoustic data classification methods using deep learning for shoreline surveillance,” Sensors, vol. 22, no. 6, p. 2181, 2022.
- [44]
- D. Neupane and J. Seok, “A review on deep learning-based approaches for automatic sonar target recognition,” Electronics, vol. 9, no. 11, p. 1972, 2020.
- [45]
- S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” Advances in neural information processing systems, vol. 30, 2017.
- [46]
- R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 618–626.
- [47]
- H. T. T. Nguyen, H. Q. Cao, K. V. T. Nguyen, and N. D. K. Pham, “Evaluation of explainable artificial intelligence: Shap, lime, and cam,” in Proceedings of the FPT AI Conference, 2021, pp. 1–6.
- [48]
- M. Bhandari, T. B. Shahi, B. Siku, and A. Neupane, “Explanatory classification of cxr images into covid-19, pneumonia and tuberculosis using deep learning and xai,” Computers in Biology and Medicine, vol. 150, p. 106156, 2022.
- [49]
- I. Kakogeorgiou and K. Karantzalos, “Evaluating explainable artificial intelligence methods for multi-label deep learning classification tasks in remote sensing,” International Journal of Applied Earth Observation and Geoinformation, vol. 103, p. 102520, 2021.
- [50]
- M. R. Hassan, M. F. Islam, M. Z. Uddin, G. Ghoshal, M. M. Hassan, S. Huda, and G. Fortino, “Prostate cancer classification from ultrasound and mri images using deep learning based explainable artificial intelligence,” Future Generation Computer Systems, vol. 127, pp. 462–472, 2022.
- [51]
- N. Nigar, M. Umar, M. K. Shahzad, S. Islam, and D. Abalo, “A deep learning approach based on explainable artificial intelligence for skin lesion classification,” IEEE Access, vol. 10, pp. 113 715–113 725, 2022.
- [52]
- A. Bennetot, G. Franchi, J. Del Ser, R. Chatila, and N. Diaz-Rodriguez, “Greybox xai: A neural-symbolic learning framework to produce interpretable predictions for image classification,” Knowledge-Based Systems, vol. 258, p. 109947, 2022.
- [53]
- S. Sahay, N. Omare, and K. Shukla, “An approach to identify captioning keywords in an image using lime,” in 2021 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS). IEEE, 2021, pp. 648–651.
- [54]
- D. Gunning and D. Aha, “Darpa’s explainable artificial intelligence (xai) program,” AI magazine, vol. 40, no. 2, pp. 44–58, 2019.
- [55]
- S. Walker, J. Peeples, J. Dale, J. Keller, and A. Zare, “Explainable systematic analysis for synthetic aperture sonar imagery,” in 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS. IEEE, 2021, pp. 2835–2838.
- [56]
- (2021) Lcocean side scan sonar. [Online]. Available: http://www.lcsonar.com/PRODUCT-SideScanSonar/67.html
- [57]
- (2021) Klein sonar systems mind technology. [Online]. Available: https://mind-technology.com/klein/
- [58]
- (2021) Edgetech side scan sonar. [Online]. Available: https://www.edgetech.com/product-category/side-scan-sonar/
- [59]
- Huoguanying, “SeabedObjects: Ship and Airplane Dataset,” https://github.com/huoguanying/SeabedObjects-Ship-and-Airplane-dataset, 2023.
- [60]
- D. P. Zhang, D. M. Ning, Z. Zhang, H. Li, Y. Zhou, P. Y. Fan, and P. D. Liu, “Sonar common target detection dataset (sctd) 1.0,” https://github.com/freepoet/SCTD, 2023.
- [61]
- Z. Reitermanova et al., “Data splitting,” in WDS, vol. 10. Matfyzpress Prague, 2010, pp. 31–36.
- [62]
- T. Cody, E. Lanus, D. D. Doyle, and L. Freeman, “Systematic training and testing for machine learning using combinatorial interaction testing,” in 2022 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW). IEEE, 2022, pp. 102–109.
- [63]
- W. G. Cochran, Sampling techniques. john wiley & sons, 1977.
- [64]
- K. Weiss, T. M. Khoshgoftaar, and D. Wang, “A survey of transfer learning,” Journal of Big data, vol. 3, no. 1, pp. 1–40, 2016.
- [65]
- R. Ribani and M. Marengoni, “A survey of transfer learning for convolutional neural networks,” in 2019 32nd SIBGRAPI conference on graphics, patterns and images tutorials (SIBGRAPI-T). IEEE, 2019, pp. 47–57.
- [66]
- D. Sarkar, R. Bali, and T. Ghosh, Hands-On Transfer Learning with Python: Implement advanced deep learning and neural network models using TensorFlow and Keras. Packt Publishing Ltd, 2018.
- [67]
- J. Deng, “A large-scale hierarchical image database,” Proc. of IEEE Computer Vision and Pattern Recognition, 2009, 2009.
- [68]
- “Keras application 2023,” https://keras.io/api/applications/. [Online]. Available: https://keras.io/api/applications/
- [69]
- S. Kotsiantis, D. Kanellopoulos, P. Pintelas et al., “Handling imbalanced datasets: A review,” GESTS international transactions on computer science and engineering, vol. 30, no. 1, pp. 25–36, 2006.
- [70]
- R. Mohammed, J. Rawashdeh, and M. Abdullah, “Machine learning with oversampling and undersampling techniques: overview study and experimental results,” in 2020 11th international conference on information and communication systems (ICICS). IEEE, 2020, pp. 243–248.
- [71]
- C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmentation for deep learning,” Journal of big data, vol. 6, no. 1, pp. 1–48, 2019.
- [72]
- D. Matsuoka, “Classification of imbalanced cloud image data using deep neural networks: performance improvement through a data science competition,” Progress in Earth and Planetary Science, vol. 8, no. 1, pp. 1–11, 2021.
- [73]
- S. Kotsiantis and P. Pintelas, “Mixture of expert agents for handling imbalanced data sets,” Annals of Mathematics, Computing & Teleinformatics, vol. 1, no. 1, pp. 46–55, 2003.
- [74]
- N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,” Journal of artificial intelligence research, vol. 16, pp. 321–357, 2002.
- [75]
- A. B. Arrieta, N. Díaz-Rodríguez, J. Del Ser, A. Bennetot, S. Tabik, A. Barbado, S. García, S. Gil-López, D. Molina, R. Benjamins et al., “Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai,” Information fusion, vol. 58, pp. 82–115, 2020.
- [76]
- B. Mahbooba, M. Timilsina, R. Sahal, and M. Serrano, “Explainable artificial intelligence (xai) to enhance trust management in intrusion detection systems using decision tree model,” Complexity, vol. 2021, pp. 1–11, 2021.
- [77]
- M. P. Neto and F. V. Paulovich, “Explainable matrix-visualization for global and local interpretability of random forest classification ensembles,” IEEE Transactions on Visualization and Computer Graphics, vol. 27, no. 2, pp. 1427–1437, 2020.
- [78]
- M. Robnik-Šikonja and M. Bohanec, “Perturbation-based explanations of prediction models,” Human and Machine Learning: Visible, Explainable, Trustworthy and Transparent, pp. 159–175, 2018.
- [79]
- B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learning deep features for discriminative localization,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2921–2929.
- [80]
- M. Narayanan, E. Chen, J. He, B. Kim, S. Gershman, and F. Doshi-Velez, “How do humans understand explanations from machine learning systems? an evaluation of the human-interpretability of explanation,” arXiv preprint arXiv:1802.00682, 2018.
- [81]
- P. J. Phillips, C. A. Hahn, P. C. Fontana, D. A. Broniatowski, and M. A. Przybocki, “Four principles of explainable artificial intelligence,” Gaithersburg, Maryland, vol. 18, 2020.
- [82]
- B. V. Kumar, “An extensive survey on superpixel segmentation: A research perspective,” Archives of Computational Methods in Engineering, pp. 1–19, 2023.
- [83]
- Ž. Vujović et al., “Classification model evaluation metrics,” International Journal of Advanced Computer Science and Applications, vol. 12, no. 6, pp. 599–606, 2021.
- [84]
- M. Grandini, E. Bagli, and G. Visani, “Metrics for multi-class classification: an overview,” arXiv preprint arXiv:2008.05756, 2020.
- [85]
- V. L. Parsons, “Stratified sampling,” Wiley StatsRef: Statistics Reference Online, pp. 1–11, 2014.
- [86]
- X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, Y. Qiao, and C. Change Loy, “Esrgan: Enhanced super-resolution generative adversarial networks,” in Proceedings of the European conference on computer vision (ECCV) workshops, 2018, pp. 0–0.
- [87]
- G. Divyabarathi, S. Shailesh, and M. Judy, “Object classification in underwater sonar images using transfer learning based ensemble model,” in 2021 International Conference on Advances in Computing and Communications (ICACC). IEEE, 2021, pp. 1–4.
- [88]
- M. Najibzadeh, A. Mahmoodzadeh, and M. Khishe, “Active sonar image classification using deep convolutional neural network evolved by robust comprehensive grey wolf optimizer,” Neural Processing Letters, pp. 1–24, 2023.
- [89]
- X. Wang, J. Jiao, J. Yin, W. Zhao, X. Han, and B. Sun, “Underwater sonar image classification using adaptive weights convolutional neural network,” Applied Acoustics, vol. 146, pp. 145–154, 2019.
- [90]
- J. d. C. V. Fernandes, N. N. de Moura Junior, and J. M. de Seixas, “Deep learning models for passive sonar signal classification of military data,” Remote Sensing, vol. 14, no. 11, p. 2648, 2022.
- [91]
- Y. Zhou and S. Chen, “Research on lightweight improvement of sonar image classification network,” in Journal of Physics: Conference Series, vol. 1883, no. 1. IOP Publishing, 2021, p. 012140.
- [92] A. H. Oveis, E. Giusti, S. Ghio, G. Meucci, and M. Martorella, “Lime-assisted automatic target recognition with sar images: Towards incremental learning and explainability,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023.




No comments:
Post a Comment